在 Android 中使用 System.load 加载一个 so 时,是通过 ElfReader 去解析这个 so 的重要结构及属性的,本文将对 ELF 的结构,链接过程,装载过程进行分析,并研究 ELF 在 AOSP 中的解析过程
# ELF 结构简析
ELF 文件主要分为 3 个部分:
- ELF Header
描述整个文件的组织 - Program Header Table
包含了运行时加载程序所需要的信息 - Section Header Table
包含了链接时所需要用到的信息
# ELF Header
//https://github.com/bminor/glibc/blob/glibc-2.27/elf/elf.h | |
#define EI_NIDENT (16) | |
typedef struct | |
{ | |
unsigned char e_ident[EI_NIDENT]; /* Magic number and other info */ | |
Elf32_Half e_type; /* Object file type */ | |
Elf32_Half e_machine; /* Architecture */ | |
Elf32_Word e_version; /* Object file version */ | |
Elf32_Addr e_entry; /* Entry point virtual address */ | |
Elf32_Off e_phoff; /* Program header table file offset */ | |
Elf32_Off e_shoff; /* Section header table file offset */ | |
Elf32_Word e_flags; /* Processor-specific flags */ | |
Elf32_Half e_ehsize; /* ELF header size in bytes */ | |
Elf32_Half e_phentsize; /* Program header table entry size */ | |
Elf32_Half e_phnum; /* Program header table entry count */ | |
Elf32_Half e_shentsize; /* Section header table entry size */ | |
Elf32_Half e_shnum; /* Section header table entry count */ | |
Elf32_Half e_shstrndx; /* Section header string table index */ | |
} Elf32_Ehdr; |
# e_ident[EI_NIDENT]
该变量给出了用于解码和解释文件中与机器无关的数据的方式。这个数组对于不同的下标的含义如下
| 宏名称 | 下标 | 目的 |
|---|---|---|
| EI_MAG0 | 0 | 文件标识 |
| EI_MAG1 | 1 | 文件标识 |
| EI_MAG2 | 2 | 文件标识 |
| EI_MAG3 | 3 | 文件标识 |
| EI_CLASS | 4 | 文件类 |
| EI_DATA | 5 | 数据编码 |
| EI_VERSION | 6 | 文件版本 |
| EI_PAD | 7 | 补齐字节开始处 |
# e_ident[EI_MAG0…EI_MAG3]
这是 ELF 文件的头 4 个字节,被称作 “魔数”,标识该文件是一个 ELF 目标文件。
| 名称 | 值 | 位置 |
|---|---|---|
| ELFMAG0 | 0x7f | e_ident[EI_MAG0] |
| ELFMAG1 | ‘E’ | e_ident[EI_MAG1] |
| ELFMAG2 | ‘L’ | e_ident[EI_MAG2] |
| ELFMAG3 | ‘F’ | e_ident[EI_MAG3] |
# e_ident[EI_CLASS]
标识文件的类型或容量
| 名称 | 值 | 意义 |
|---|---|---|
| ELFCLASSNONE | 0 | 无效类型 |
| ELFCLASS32 | 1 | 32 位文件 |
| ELFCLASS64 | 2 | 64 位文件 |
# e_ident[EI_DATA]
给出目标文件中的特定处理器数据的编码方式
| 名称 | 值 | 意义 |
|---|---|---|
| ELFDATANONE | 0 | 无效数据编码 |
| ELFDATA2LSB | 1 | 小端 |
| ELFDATA2MSB | 2 | 大端 |
# e_type
e_type 标识目标文件类型。
| 名称 | 值 | 意义 |
|---|---|---|
| ET_NONE | 0 | 无文件类型 |
| ET_REL | 1 | 可重定位文件 |
| ET_EXEC | 2 | 可执行文件 |
| ET_DYN | 3 | 共享目标文件 |
| ET_CORE | 4 | 核心转储文件 |
| ET_LOPROC | 0xff00 | 处理器指定下限 |
| ET_HIPROC | 0xffff | 处理器指定上限 |
# e_machine
这一项指定了当前文件可以运行的机器架构,EM 是 ELF Machine 的简写
| 名称 | 值 | 意义 |
|---|---|---|
| EM_NONE | 0 | 无机器类型 |
| EM_M32 | 1 | AT&T WE 32100 |
| EM_SPARC | 2 | SPARC |
| EM_386 | 3 | Intel 80386 |
| EM_68K | 4 | Motorola 68000 |
| EM_88K | 5 | Motorola 88000 |
| EM_860 | 7 | Intel 80860 |
| EM_MIPS | 8 | MIPS RS3000 |
# e_version
标识目标文件的版本。
| 名称 | 值 | 意义 |
|---|---|---|
| EV_NONE | 0 | 无效版本 |
| EV_CURRENT | 1 | 当前版本 |
# e_entry
这一项为系统转交控制权给 ELF 中相应代码的虚拟地址。如果没有相关的入口项,则这一项为 0。
例如当 e_entry 为 00 00 80 00 时,得到可执行程序的入口地址为 0x8000
它是程序的入口虚拟地址,注意不是 main 函数的地址,而是 .text 段的首地址 _start 。当然这也要求程序本身非 PIE ( -no-pie ) 编译的且 ASLR 关闭的情况下,对于非 ET_EXEC 类型通常并不是实际的虚拟地址值.
# e_phoff
这一项给出程序头部表在文件中的字节偏移(Program Header table OFFset)。如果文件中没有程序头部表,则为 0。
# e_shoff
这一项给出节头表在文件中的字节偏移( Section Header table OFFset )。如果文件中没有节头表,则为 0。
# e_flags
这一项给出文件中与特定处理器相关的标志,这些标志命名格式为 EF_machine_flag 。
# e_ehsize
这一项给出 ELF 文件头部的字节长度(ELF Header Size)。
# e_phentsize
这一项给出程序头部表中每个表项的字节长度(Program Header ENTry SIZE)。每个表项的大小相同。
# e_phnum
这一项给出程序头部表的项数( Program Header entry NUMber )。因此, e_phnum 与 e_phentsize 的乘积即为程序头部表的字节长度。如果文件中没有程序头部表,则该项值为 0。
# e_shentsize
这一项给出节头的字节长度(Section Header ENTry SIZE)。一个节头是节头表中的一项;节头表中所有项占据的空间大小相同。
# e_shnum
这一项给出节头表中的项数(Section Header NUMber)。因此, e_shnum 与 e_shentsize 的乘积即为节头表的字节长度。如果文件中没有节头表,则该项值为 0。
# e_shstrndx
这一项给出节头表中与节名字符串表相关的表项的索引值(Section Header table InDeX related with section name STRing table), 即 section table 中的第 e_shstrndx 项元素,保存了所有 section table 名称的字符串信息。如果文件中没有节名字符串表,则该项值为 SHN_UNDEF
# Program Header
Program Header Table 是一个结构体数组,每一个元素的类型是 Elf32_Phdr ,描述了一个段或者其它系统在准备程序执行时所需要的信息。其中,ELF 头中的 e_phentsize 和 e_phnum 指定了该数组每个元素的大小以及元素个数。一个目标文件的段包含一个或者多个节。程序的头部只有对于可执行文件和共享目标文件有意义。
可以说,Program Header Table 就是专门为 ELF 文件运行时中的段所准备的。
Elf32_Phdr 的数据结构如下
typedef struct | |
{ | |
Elf32_Word p_type; /* Segment type */ | |
Elf32_Off p_offset; /* Segment file offset */ | |
Elf32_Addr p_vaddr; /* Segment virtual address */ | |
Elf32_Addr p_paddr; /* Segment physical address */ | |
Elf32_Word p_filesz; /* Segment size in file */ | |
Elf32_Word p_memsz; /* Segment size in memory */ | |
Elf32_Word p_flags; /* Segment flags */ | |
Elf32_Word p_align; /* Segment alignment */ | |
} Elf32_Phdr; |
每个字段的说明如下
| 字段 | 说明 |
|---|---|
| p_type | 该字段为段的类型,或者表明了该结构的相关信息。 |
| p_offset | 该字段给出了从文件开始到该段开头的第一个字节的偏移。 |
| p_vaddr | 该字段给出了该段第一个字节在内存中的虚拟地址。 |
| p_paddr | 该字段仅用于物理地址寻址相关的系统中, 由于 “System V” 忽略了应用程序的物理寻址,可执行文件和共享目标文件的该项内容并未被限定。 |
| p_filesz | 该字段给出了文件镜像中该段的大小,可能为 0。 |
| p_memsz | 该字段给出了内存镜像中该段的大小,可能为 0。 |
| p_flags | 该字段给出了与段相关的标记。 |
| p_align | 可加载的程序的段的 p_vaddr 以及 p_offset 的大小必须是 page 的整数倍。该成员给出了段在文件以及内存中的对齐方式。如果该值为 0 或 1 的话,表示不需要对齐。除此之外,p_align 应该是 2 的整数指数次方,并且 p_vaddr 与 p_offset 在模 p_align 的意义下,应该相等。 |
# p_type
可执行文件中的段类型如下
| 名字 | 取值 | 说明 |
|---|---|---|
| PT_NULL | 0 | 表明段未使用,其结构中其他成员都是未定义的。 |
| PT_LOAD | 1 | 此类型段为一个可加载的段,大小由 p_filesz 和 p_memsz 描述。文件中的字节被映射到相应内存段开始处。如果 p_memsz 大于 p_filesz,“剩余” 的字节都要被置为 0。p_filesz 不能大于 p_memsz。可加载的段在程序头部中按照 p_vaddr 的升序排列。 |
| PT_DYNAMIC | 2 | 此类型段给出动态链接信息。 |
| PT_INTERP | 3 | 此类型段给出了一个以 NULL 结尾的字符串的位置和长度,该字符串将被当作解释器调用。这种段类型仅对可执行文件有意义(也可能出现在共享目标文件中)。此外,这种段在一个文件中最多出现一次。而且这种类型的段存在的话,它必须在所有可加载段项的前面。 |
| PT_NOTE | 4 | 此类型段给出附加信息的位置和大小。 |
| PT_SHLIB | 5 | 该段类型被保留,不过语义未指定。而且,包含这种类型的段的程序不符合 ABI 标准。 |
| PT_PHDR | 6 | 该段类型的数组元素如果存在的话,则给出了程序头部表自身的大小和位置,既包括在文件中也包括在内存中的信息。此类型的段在文件中最多出现一次。此外,只有程序头部表是程序的内存映像的一部分时,它才会出现。如果此类型段存在,则必须在所有可加载段项目的前面。 |
| PT_LOPROC~PT_HIPROC | 0x70000000 ~0x7fffffff | 此范围的类型保留给处理器专用语义。 |
# p_flags
被系统加载到内存中的程序至少有一个可加载的段。当系统为可加载的段创建内存镜像时,它会按照 p_flags 将段设置为对应的权限。可能的段权限位有

其中,所有在 PF_MASKPROC 中的比特位都是被保留用于与处理器相关的语义信息。
如果一个权限位被设置为 0,这种类型的段是不可访问的。实际的内存权限取决于相应的内存管理单元,不同的系统可能操作方式不一样。尽管所有的权限组合都是可以的,但是系统一般会授予比请求更多的权限。在任何情况下,除非明确说明,一个段不会有写权限。下面给出了所有的可能组合。
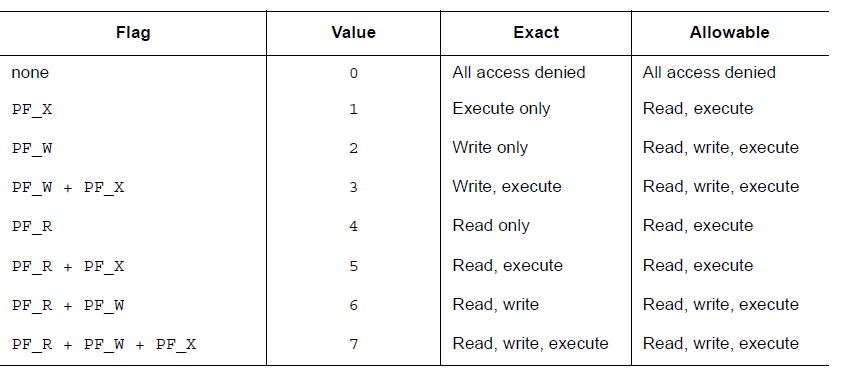
例如,一般来说,.text 段一般具有读和执行权限,但是不会有写权限。数据段一般具有写,读,以及执行权限。
# Section Header
ELF 头中的 e_shoff 项给出了从文件开头到节头表位置的字节偏移。 e_shnum 告诉了我们节头表包含的项数; e_shentsize 给出了每一项的字节大小。
节头表是一个数组,每个数组的元素的类型是 ELF32_Shdr ,每一个元素都描述了一个节区的概要内容。每个节区头部可以用下面的数据结构进行描述:
typedef struct | |
{ | |
Elf32_Word sh_name; /* Section name (string tbl index) */ | |
Elf32_Word sh_type; /* Section type */ | |
Elf32_Word sh_flags; /* Section flags */ | |
Elf32_Addr sh_addr; /* Section virtual addr at execution */ | |
Elf32_Off sh_offset; /* Section file offset */ | |
Elf32_Word sh_size; /* Section size in bytes */ | |
Elf32_Word sh_link; /* Link to another section */ | |
Elf32_Word sh_info; /* Additional section information */ | |
Elf32_Word sh_addralign; /* Section alignment */ | |
Elf32_Word sh_entsize; /* Entry size if section holds table */ | |
} Elf32_Shdr; |
每个字段的含义如下
| 成员 | 说明 |
|---|---|
| sh_name | 节名称,是节区头字符串表节区中(Section Header String Table Section)的索引,因此该字段实际是一个数值。在字符串表中的具体内容是以 NULL 结尾的字符串。 |
| sh_type | 根据节的内容和语义进行分类,具体的类型下面会介绍。 |
| sh_flags | 每一比特代表不同的标志,描述节是否可写,可执行,需要分配内存等属性。 |
| sh_addr | 如果节区将出现在进程的内存映像中,此成员给出节区的第一个字节应该在进程镜像中的位置。否则,此字段为 0。 |
| sh_offset | 给出节区的第一个字节与文件开始处之间的偏移。SHT_NOBITS 类型的节区不占用文件的空间,因此其 sh_offset 成员给出的是概念性的偏移。 |
| sh_size | 此成员给出节区的字节大小。除非节区的类型是 SHT_NOBITS ,否则该节占用文件中的 sh_size 字节。类型为 SHT_NOBITS 的节区长度可能非零,不过却不占用文件中的空间。 |
| sh_link | 此成员给出节区头部表索引链接,其具体的解释依赖于节区类型。 |
| sh_info | 此成员给出附加信息,其解释依赖于节区类型。 |
| sh_addralign | 某些节区的地址需要对齐。例如,如果一个节区有一个 doubleword 类型的变量,那么系统必须保证整个节区按双字对齐。也就是说, sh_addr%sh_addralign=0 。目前它仅允许为 0,以及 2 的正整数幂数。 0 和 1 表示没有对齐约束。 |
| sh_entsize | 某些节区中存在具有固定大小的表项的表,如符号表。对于这类节区,该成员给出每个表项的字节大小。反之,此成员取值为 0。 |
# sh_type
节类型目前有下列可选范围,其中 SHT 是 Section Header Table 的简写。
| 名称 | 取值 | 说明 |
|---|---|---|
| SHT_NULL | 0 | 该类型节区是非活动的,这种类型的节头中的其它成员取值无意义。 |
| SHT_PROGBITS | 1 | 该类型节区包含程序定义的信息,它的格式和含义都由程序来决定。 |
| SHT_SYMTAB | 2 | 该类型节区包含一个符号表(SYMbol TABle)。目前目标文件对每种类型的节区都只 能包含一个,不过这个限制将来可能发生变化。 一般,SHT_SYMTAB 节区提供用于链接编辑(指 ld 而言) 的符号,尽管也可用来实现动态链接。 |
| SHT_STRTAB | 3 | 该类型节区包含字符串表( STRing TABle )。 |
| SHT_RELA | 4 | 该类型节区包含显式指定位数的重定位项( RELocation entry with Addends ),例如,32 位目标文件中的 Elf32_Rela 类型。此外,目标文件可能拥有多个重定位节区。 |
| SHT_HASH | 5 | 该类型节区包含符号哈希表( HASH table )。 |
| SHT_DYNAMIC | 6 | 该类型节区包含动态链接的信息( DYNAMIC linking )。 |
| SHT_NOTE | 7 | 该类型节区包含以某种方式标记文件的信息(NOTE)。 |
| SHT_NOBITS | 8 | 该类型节区不占用文件的空间,其它方面和 SHT_PROGBITS 相似。尽管该类型节区不包含任何字节,其对应的节头成员 sh_offset 中还是会包含概念性的文件偏移。 |
| SHT_REL | 9 | 该类型节区包含重定位表项(RELocation entry without Addends),不过并没有指定位数。例如,32 位目标文件中的 Elf32_rel 类型。目标文件中可以拥有多个重定位节区。 |
| SHT_SHLIB | 10 | 该类型此节区被保留,不过其语义尚未被定义。 |
| SHT_DYNSYM | 11 | 作为一个完整的符号表,它可能包含很多对动态链接而言不必 要的符号。因此,目标文件也可以包含一个 SHT_DYNSYM 节区,其中保存动态链接符号的一个最小集合,以节省空间。 |
| SHT_LOPROC | 0X70000000 | 此值指定保留给处理器专用语义的下界( LOw PROCessor-specific semantics )。 |
| SHT_HIPROC | OX7FFFFFFF | 此值指定保留给处理器专用语义的上界( HIgh PROCessor-specific semantics )。 |
| SHT_LOUSER | 0X80000000 | 此值指定保留给应用程序的索引下界。 |
| SHT_HIUSER | 0X8FFFFFFF | 此值指定保留给应用程序的索引上界。 |
# sh_flags
节头中 sh_flags 字段的每一个比特位都可以给出其相应的标记信息,其定义了对应的节区的内容是否可以被修改、被执行等信息。如果一个标志位被设置,则该位取值为 1,未定义的位都为 0。目前已定义值如下,其他值保留。
| 名称 | 值 | 说明 |
|---|---|---|
| SHF_WRITE | 0x1 | 这种节包含了进程运行过程中可以被写的数据。 |
| SHF_ALLOC | 0x2 | 这种节在进程运行时占用内存。对于不占用目标文件的内存镜像空间的某些控制节,该属性处于关闭状态 (off)。 |
| SHF_EXECINSTR | 0x4 | 这种节包含可执行的机器指令(EXECutable INSTRuction)。 |
| SHF_MASKPROC | 0xf0000000 | 所有在这个掩码中的比特位用于特定处理器语义。 |
# sh_link & sh_info
当节区类型的不同的时候,sh_link 和 sh_info 也会具有不同的含义。
| sh_type | sh_link | sh_info |
|---|---|---|
| SHT_DYNAMIC | 节区中使用的字符串表的节头索引 | 0 |
| SHT_HASH | 此哈希表所使用的符号表的节头索引 | 0 |
| SHT_REL/SHT_RELA | 与符号表相关的节头索引 | 重定位应用到的节的节头索引 |
| SHT_SYMTAB/SHT_DYNSYM | 操作系统特定信息,Linux 中的 ELF 文件中该项指向符号表中符号所对应的字符串节区在 Section Header Table 中的偏移。 | 操作系统特定信息 |
| other | SHN_UNDEF |
0 |
# ELF sections
# 节的分类
# .text 节
.text 节是保存了程序代码指令的代码节。一段可执行程序,如果存在 Phdr,则 .text 节就会存在于 text 段中。由于 .text 节保存了程序代码,所以节类型为 SHT_PROGBITS 。
# .rodata 节
rodata 节保存了只读的数据,如一行 C 语言代码中的字符串。由于 .rodata 节是只读的,所以只能存在于一个可执行文件的只读段中。因此,只能在 text 段(不是 data 段)中找到 .rodata 节。由于 .rodata 节是只读的,所以节类型为 SHT_PROGBITS 。
# .plt 节(过程链接表)
.plt 节也称为过程链接表(Procedure Linkage Table),其包含了动态链接器调用从共享库导入的函数所必需的相关代码。由于 .plt 节保存了代码,所以节类型为 SHT_PROGBITS 。
# .data 节
.data 节存在于 data 段中,其保存了初始化的全局变量等数据。由于 .data 节保存了程序的变量数据,所以节类型为 SHT_PROGBITS 。
# .bss 节
.bss 节存在于 data 段中,占用空间不超过 4 字节,仅表示这个节本省的空间。 .bss 节保存了未进行初始化的全局数据。程序加载时数据被初始化为 0,在程序执行期间可以进行赋值。由于 .bss 节未保存实际的数据,所以节类型为 SHT_NOBITS 。
# .got.plt 节(全局偏移表 - 过程链接表)
.got 节保存了全局偏移表。 .got 节和 .plt 节一起提供了对导入的共享库函数的访问入口,由动态链接器在运行时进行修改。由于 .got.plt 节与程序执行有关,所以节类型为 SHT_PROGBITS 。
# .dynsym 节(动态链接符号表)
.dynsym 节保存在 text 段中。其保存了从共享库导入的动态符号表。节类型为 SHT_DYNSYM 。
# .dynstr 节(动态链接字符串表)
.dynstr 保存了动态链接字符串表,表中存放了一系列字符串,这些字符串代表了符号名称,以空字符作为终止符。
# .rel.* 节(重定位表)
重定位表保存了重定位相关的信息,这些信息描述了如何在链接或运行时,对 ELF 目标文件的某部分或者进程镜像进行补充或修改。由于重定位表保存了重定位相关的数据,所以节类型为 SHT_REL 。
# .hash 节
.hash 节也称为 .gnu.hash ,其保存了一个用于查找符号的散列表。
# .symtab 节(符号表)
.symtab 节是一个 ElfN_Sym 的数组,保存了符号信息。节类型为 SHT_SYMTAB 。
# .strtab 节(字符串表)
.strtab 节保存的是符号字符串表,表中的内容会被 .symtab 的 ElfN_Sym 结构中的 st_name 引用。节类型为 SHT_STRTAB 。
# .ctors 节和.dtors 节
.ctors (构造器)节和 .dtors (析构器)节分别保存了指向构造函数和析构函数的函数指针,构造函数是在 main 函数执行之前需要执行的代码;析构函数是在 main 函数之后需要执行的代码。
# 符号表
符号是对某些类型的数据或代码(如全局变量或函数)的符号引用,函数名或变量名就是符号名。例如, printf() 函数会在动态链接符号表 .dynsym 中存有一个指向该函数的符号项(以 Elf_Sym 数据结构表示)。在大多数共享库和动态链接可执行文件中,存在两个符号表。即 .dynsym 和 .symtab 。
.dynsym 保存了引用来自外部文件符号的全局符号。如 printf 库函数。 .dynsym 保存的符号是 .symtab 所保存符合的子集, .symtab 中还保存了可执行文件的本地符号。如全局变量,代码中定义的本地函数等。
既然 .dynsym 是 .symtab 的子集,那为何要同时存在两个符号表呢?
通过 readelf -S 命令可以查看可执行文件的输出,一部分节标志位( sh_flags )被标记为了 A(ALLOC)、WA(WRITE/ALLOC)、AX(ALLOC/EXEC)。其中, .dynsym 被标记为 ALLOC,而 .symtab 则没有标记。
ALLOC 表示有该标记的节会在运行时分配并装载进入内存,而 .symtab 不是在运行时必需的,因此不会被装载到内存中。 .dynsym 保存的符号只能在运行时被解析,因此是运行时动态链接器所需的唯一符号。 .dynsym 对于动态链接可执行文件的执行是必需的,而 .symtab 只是用来进行调试和链接的。
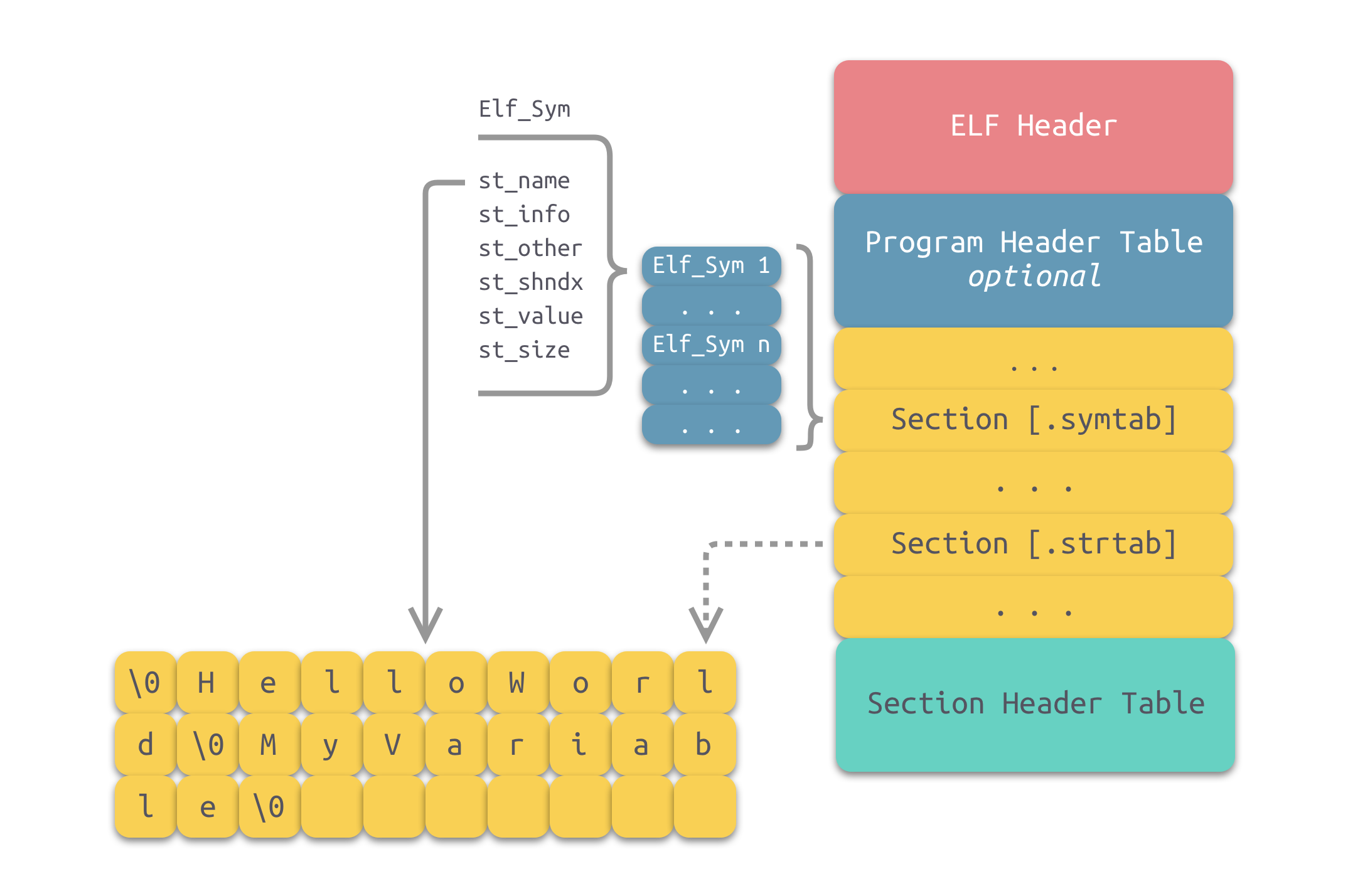
上图所示为通过符号表索引字符串表的示意图。符号表中的每一项都是一个 Elf_Sym 结构,对应可以在字符串表中索引得到一个字符串。该数据结构中成员的含义如下表所示:
| 成员 | 含义 |
|---|---|
| st_name | 符号名。该值为该符号名在字符串表中的偏移地址。 |
| st_value | 符号对应的值。存放符号的值(可能是地址或位置偏移量)。 |
| st_size | 符号的大小。 |
| st_other | 0 |
| st_shndx | 符号所在的节 |
| st_info | 符号类型及绑定属性 |
使用 readelf 工具我们也能够看到符号表的相关信息。
$ readelf -s hello.o
Symbol table '.symtab' contains 11 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS hello.c
2: 0000000000000000 0 SECTION LOCAL DEFAULT 1
3: 0000000000000000 0 SECTION LOCAL DEFAULT 3
4: 0000000000000000 0 SECTION LOCAL DEFAULT 4
5: 0000000000000000 0 SECTION LOCAL DEFAULT 5
6: 0000000000000000 0 SECTION LOCAL DEFAULT 7
7: 0000000000000000 0 SECTION LOCAL DEFAULT 8
8: 0000000000000000 0 SECTION LOCAL DEFAULT 6
9: 0000000000000000 21 FUNC GLOBAL DEFAULT 1 main
10: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND puts
# 字符串表
类似于符号表,在大多数共享库和动态链接可执行文件中,也存在两个字符串表。即 .dynstr 和 .strtab ,分别对应于 .dynsym 和 symtab 。此外,还有一个 .shstrtab 的节头字符串表,用于保存节头表中用到的字符串,可通过 sh_name 进行索引。
ELF 文件中所有字符表的结构基本一致,如上图所示。
# 重定位表
重定位就是将符号定义和符号引用进行连接的过程。可重定位文件需要包含描述如何修改节内容的相关信息,从而使可执行文件和共享目标文件能够保存进程的程序镜像所需要的正确信息。
重定位表是进行重定位的重要依据。我们可以使用 objdump 工具查看目标文件的重定位表:
$ objdump -r hello.o
hello.o: file format elf64-x86-64
RELOCATION RECORDS FOR [.text]:
OFFSET TYPE VALUE
0000000000000005 R_X86_64_32 .rodata
000000000000000a R_X86_64_PC32 puts-0x0000000000000004
RELOCATION RECORDS FOR [.eh_frame]:
OFFSET TYPE VALUE
0000000000000020 R_X86_64_PC32 .text
重定位表是一个 Elf_Rel 类型的数组结构,每一项对应一个需要进行重定位的项。 其成员含义如下表所示:
| 成员 | 含义 |
|---|---|
| r_offset | 重定位入口的偏移。对于可重定位文件来说,这个值是该重定位入口所要修正的位置的第一个字节相对于节起始的偏移;对于可执行文件或共享对象文件来说,这个值是该重定位入口所要修正的位置的第一个字节的虚拟地址 |
| r_info | 重定位入口的类型和符号。因为不同处理器的指令系统不一样,所以重定位所要修正的指令地址格式也不一样。每种处理器都有自己的一套重定位入口的类型。对于可执行文件和共享目标文件来说,它们的重定位入口是动态链接类型的。 |
重定位是目标文件链接成为可执行文件的关键。
# ELF 的链接过程
此处的内容来源于计算机那些事 (5)—— 链接、静态链接、动态链接,仅作学习记录和备份用
# 链接概述
模块化设计是软件开发中最常用的设计思想。链接(Linking) 本质上就是把各个模块之间相互引用的部分处理好,使得各个模块之间能够正确衔接。比如:
我们在模块
main.c中使用另一个模块func.c中的foo()函数。我们在main.c模块中每一处调用foo时都必须确切知道foo函数的地址。但由于每个模块都是单独编译的。编译器在编译main.c的时候并不知道foo函数的地址。所以编译器会暂时把这些调用foo的指令的目标地址搁置,等待最后链接时由链接器将这些指令的目标地址修正。这就是静态链接最基本的过程和作用。
如下图所示为最基本的静态链接过程示意图。每个模块的源代码文件(如 .c )文件经过编译器编译成目标文件(Object File,一般扩展名为 .o 或 .obj )。目标文件和 库(Library) 一起链接形成最终的可执行文件。
其中,最常见的库就是运行时库(Runtime Library),它是支持程序运行的基本函数的集合。库本质上是一组目标文件的包,由一些最常用的代码编译成目标文件后打包而成。
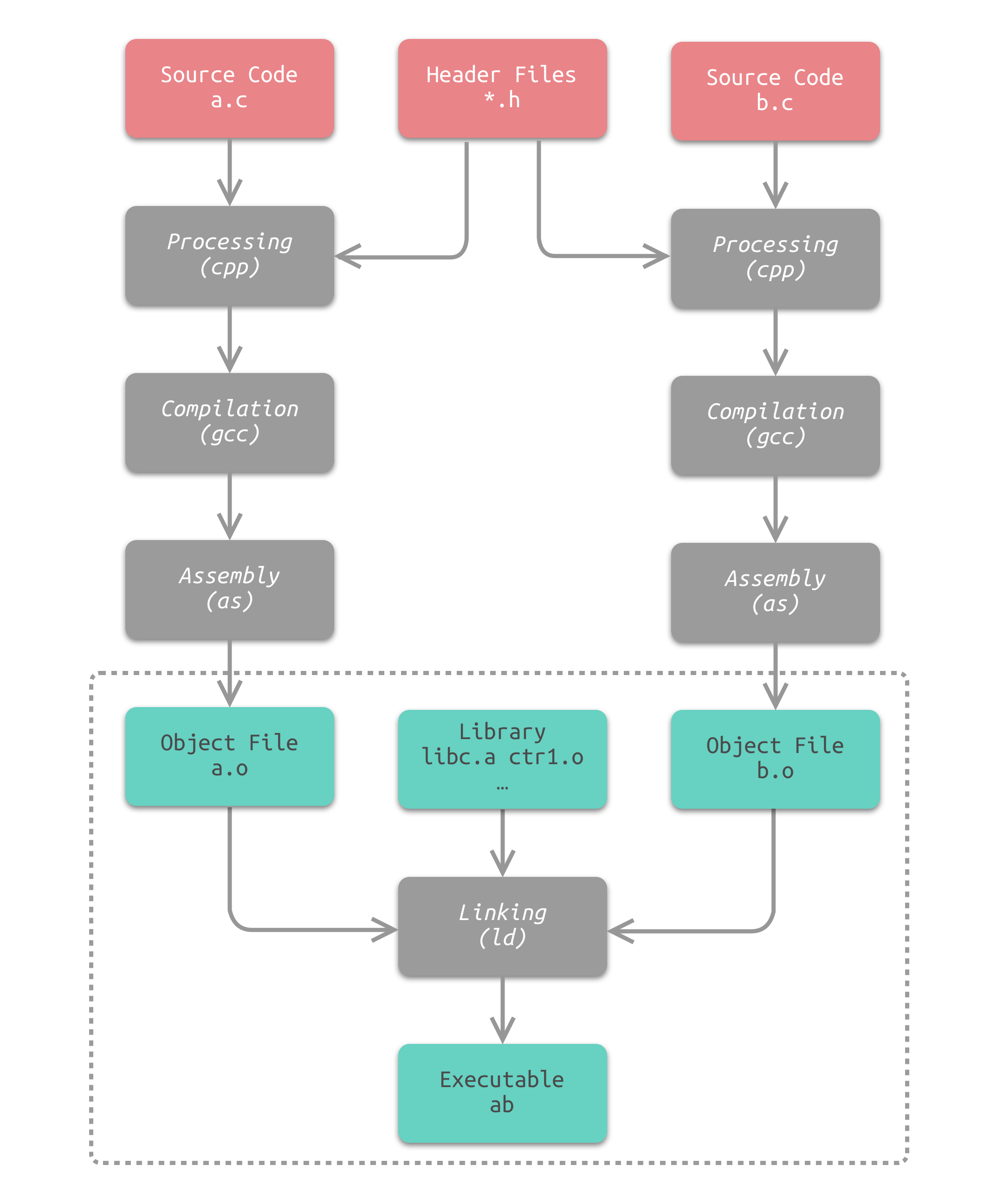
链接过程主要包含了三个步骤:
- 地址与空间分配(Address and Storage Allocation)
- 符号解析(Symbol Resolution)
- 重定位(Relocation)
下面,我们以两个源代码文件 a.c 和 b.c 为例展开分析。
// a.c
extern int shared;
int main() {
int a = 100;
swap(&a, &shared);
}
// b.c
int shared = 1;
void swap(int *a, int *b) {
*a ^= *b ^= *a ^= *b;
}
其中, b.c 中定义了两个全局符号:变量 shared 、函数 swap ; a.c 中定义了一个全局符号: main 。 a.c 引用了 b.c 中的 swap 和 shared 。接下来我们要将两个目标文件链接在一起并最终形成一个执行程文件 ab 。
使用 gcc -c 命令我们可以分别编译得到 a.o 和 b.o 两个目标文件。
# 地址与空间分配
在介绍 ELF 文件结构关于段与节的区别时,我们就提到过可执行文件中的段是由目标文件中的节合并而来的。那么,我们的第一个问题是:对于多个输入目标文件,链接器如何将它们的各个节合并到输出文件呢?或者说,输出文件中的空间如何分配给输入文件。
# 按序叠加
一个最简单的方案就是将输入的文件按序叠加,如下图所示。
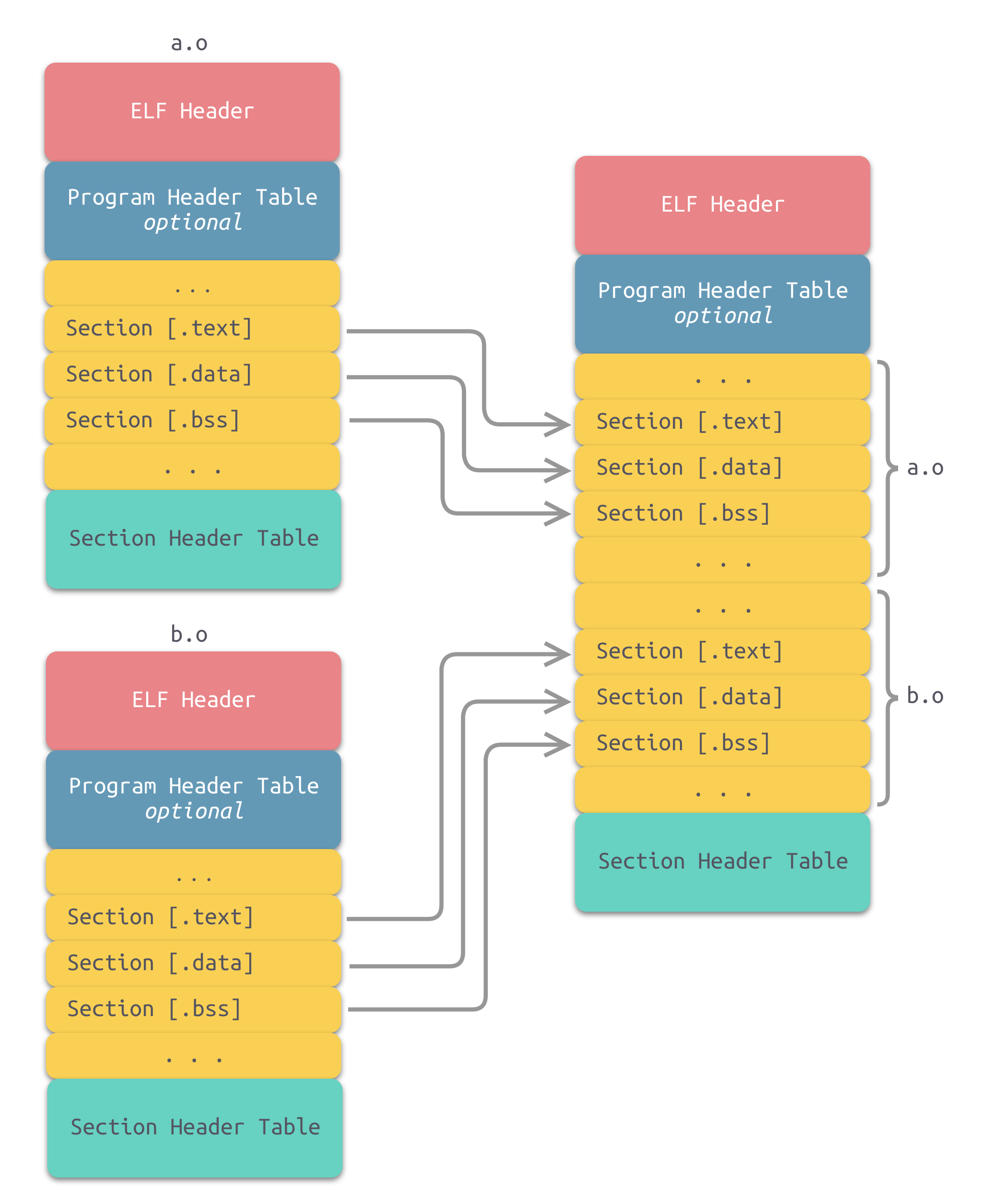
虽然这种方法非常简单,但是它存在一个问题:在有很多输入文件的情况下,输出文件会有很多零散的节。这种做法非常浪费空间,因为每个节都需要有一定的地址和空间对齐要求。x86 硬件的对齐要求是 4KB。如果一个节的大小只有 1 个字节,它也要在内存在重用 4KB。这样会造成大量内部碎片。所以不是一个好的方案。
# 合并相似节
一个更加实际的方法便是合并相同性质的节,比如:将所有输入文件的 .text 节合并到输出文件的 text 段(注意,此时出现了段和节两个概念),如下图所示。
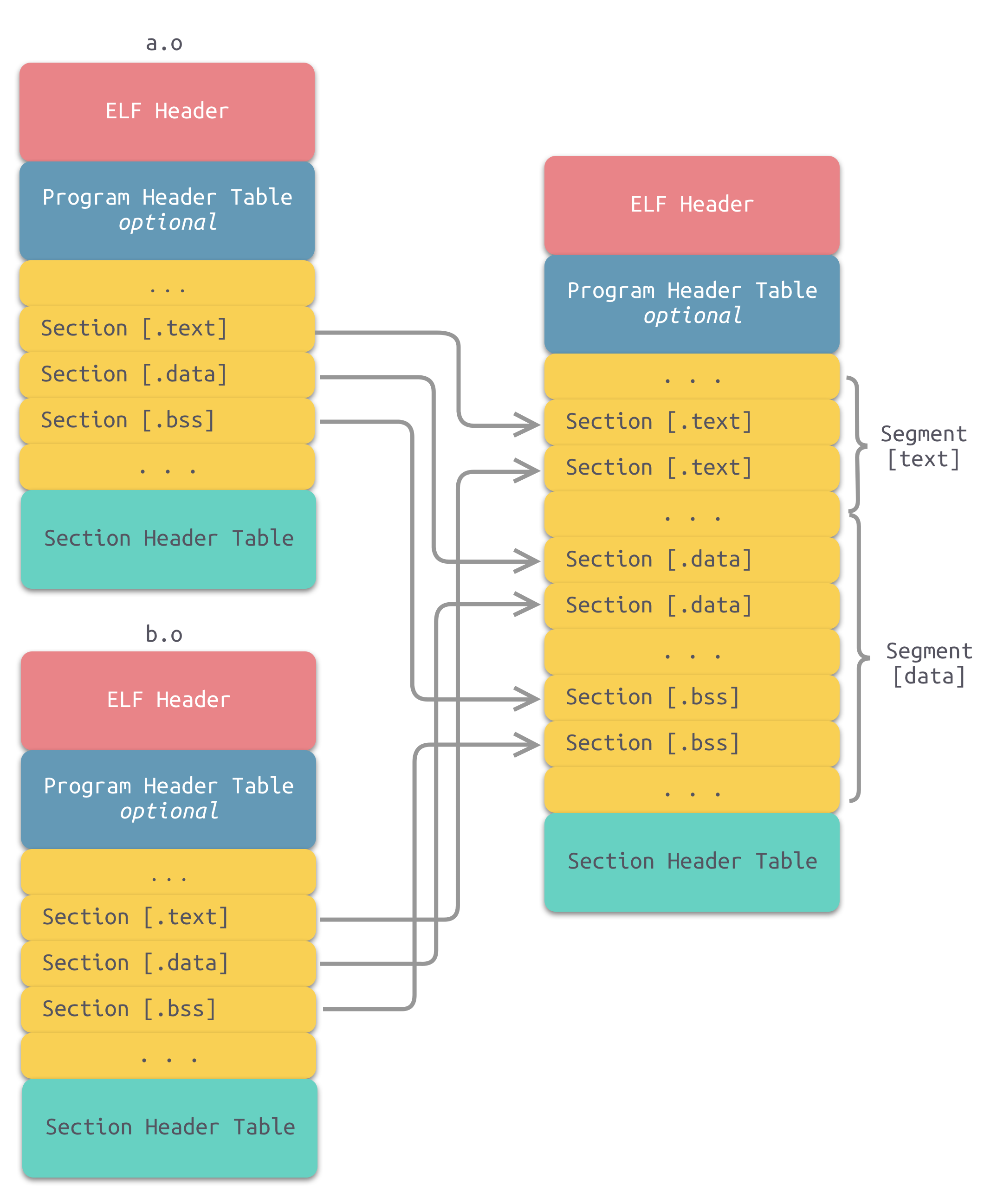
其中 .bss 节在目标文件和可执行文件中不占用文件的空间,但是它在装载时占用地址空间。事实上,这里的空间和地址有两层含义:
- 在输出的可执行文件中的空间
- 在装载后的虚拟地址中的空间
对于有实际数据的节,如 .text 和 .data ,它们在文件中和虚拟地址中都要分配空间,因为它们在这两者中都存在;对于 .bss 来,分配空间的意义只局限于虚拟地址空间,因为它在文件中并没有内容。我们在这里谈到的空间分配只关注于虚拟地址空间的分配,因为这关系到链接器后面的关于地址计算的步骤,而可执行文件本身的空间分配与链接的关系并不大。
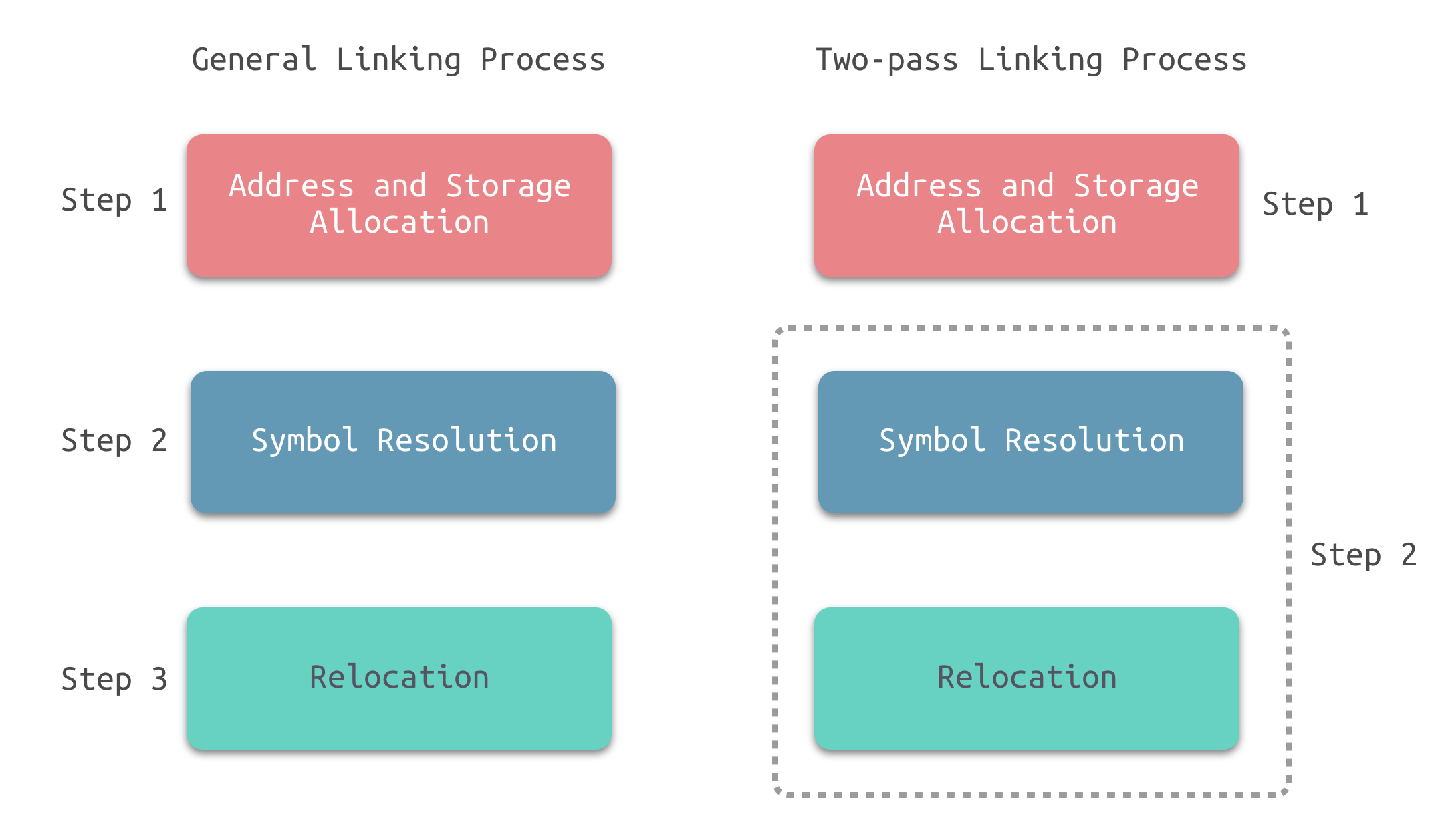
现在的链接器空间分配的策略基本上都采用 “合并相似节” 的方法,使用这种方法的链接器一般采用一种叫 两步链接(Two-pass Linking) 的方法。即整个链接过程分为两步:
- 第一步 地址与空间分配
扫描所有的输入目标文件,获得它们的各个节的长度、属性、位置,并将输入目标文件中的符号表中所有的符号定义和符号引用收集起来,统一放到一个全局的符号表。这一步,链接器能够获得所有输入目标文件的节的长度,并将它们合并,计算出输出文件中各个节合并后的长度与位置,并建立映射关系。 - 第二步 符号解析与重定位
使用前一步中收集到的所有信息,读取输入文件中节的输数据、重定位信息,并且进行符号解析与重定位、调整代码、调整代码中的地址等。事实上,第二步是链接过程的核心,尤其是重定位。
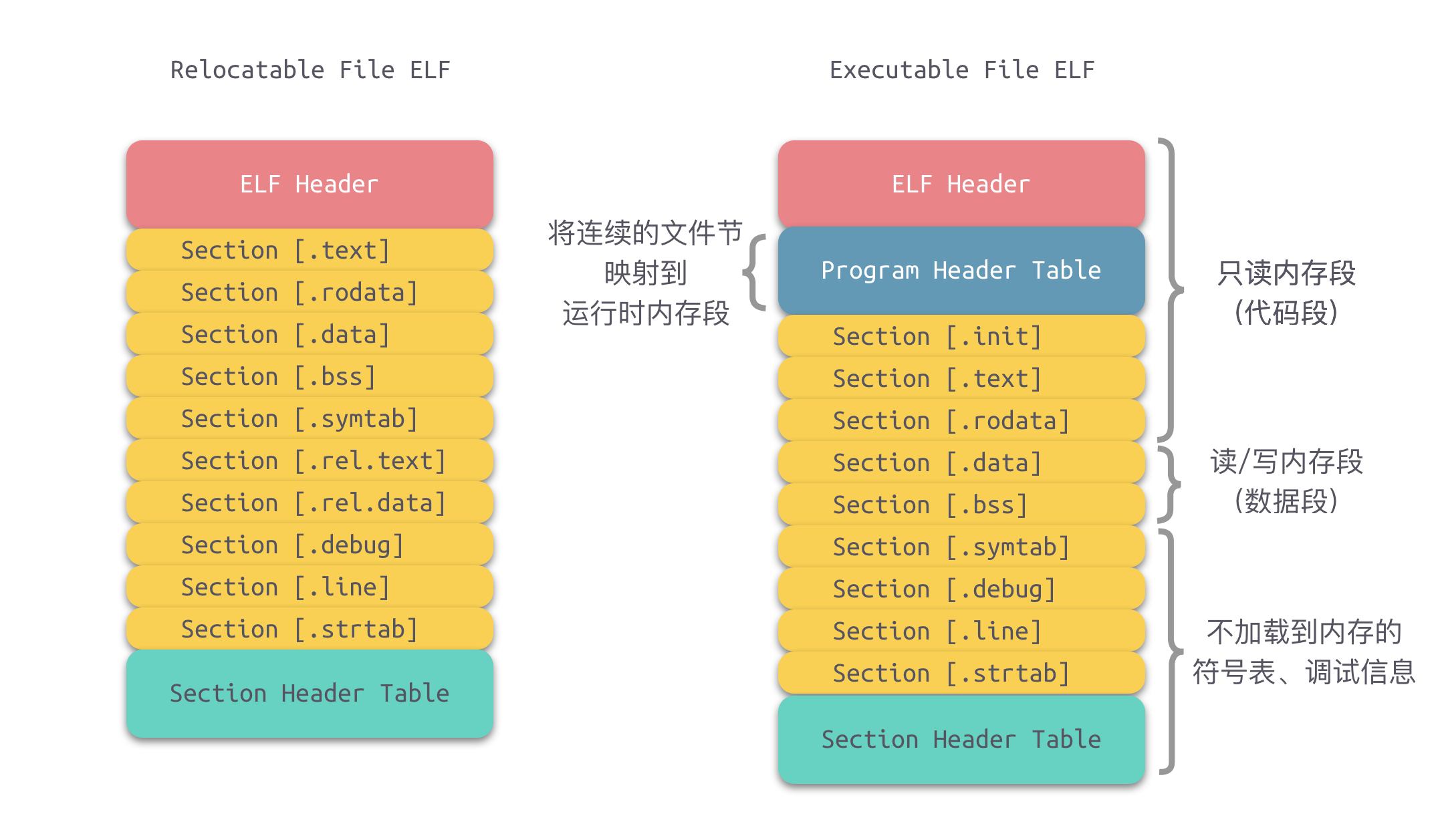
在地址与空间分配步骤完成之后,相似权限的节会被合并成段,并生成了 ELF 文件结构一文中没有介绍的 程序头表(Program Header Table) 结构。如下右图可执行文件结构所示,主要生成两个段:代码段( text 段)、数据段( data 段 )。
我们使用 ld 或 gcc 将 a.o 和 b.o 链接起来,然后使用 objdump 工具来查看链接前后的地址分配情况。
$ objdump -h a.o
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 0000004f 0000000000000000 0000000000000000 00000040 2**0
CONTENTS, ALLOC, LOAD, RELOC, READONLY, CODE
1 .data 00000000 0000000000000000 0000000000000000 0000008f 2**0
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000000 0000000000000000 0000000000000000 0000008f 2**0
ALLOC
...
$ objdump -h b.o
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 0000004b 0000000000000000 0000000000000000 00000040 2**0
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .data 00000004 0000000000000000 0000000000000000 0000008c 2**2
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000000 0000000000000000 0000000000000000 00000090 2**0
ALLOC
...
$ objdump -h ab
Sections:
Idx Name Size VMA LMA File off Algn
...
13 .text 00000202 0000000000400450 0000000000400450 00000450 2**4
CONTENTS, ALLOC, LOAD, READONLY, CODE
...
24 .data 00000014 0000000000601028 0000000000601028 00001028 2**3
CONTENTS, ALLOC, LOAD, DATA
25 .bss 00000004 000000000060103c 000000000060103c 0000103c 2**0
ALLOC
...
可以发现,链接前目标文件中所有节的 VMA(Virtual Memory Address) 都是 0,因为虚拟空间还没有分配。链接后,可执行文件 ab 中各个节被分配到了相应的虚拟地址,如 .text 节被分配到了地址 0x0000000000400450 。
那么,为什么链接器要将可执行文件 ab 的 .text 节分配到 0x0000000000400450 ?而不是从虚拟空间的 0 地址开始分配呢?这涉及到操作系统的进程虚拟地址空间的分配规则。在 Linux x86-64 系统中,代码段总是从 0x0000000000400000 开始的,另外 .text 节之前还有 ELF Header 、 Program Header Table 、 .init 等占用了一定的空间,所以就被分配到了 0x0000000000400450 。
# 符号解析
在两步链接中,这一步和重定位被合并成了一步,这是因为重定位的过程是伴随着符号解析的。这里我们分开介绍。
链接器解析符号引用的方法是将每个引用与它输入的可重定位目标文件的符号表中的一个确定的符号定义关联起来。对那些和引用定义在相同模块的局部符号的引用,符号解析是非常简单的。编译器只允许每个模块中每个局部符号有一个定义。静态局部变量也会有本地链接器符号,编译器还要确保它们拥有唯一的名字。
然而,对于全局符号的解析要复杂得多。当编译器遇到一个不是在当前模块中定义的符号(变量或函数名)时,会假设该符号是在其他某个模块中定义的,生成一个链接器符号表条目,并把它交给链接器处理。如果链接器在它的任何输入模块中都找不到这个被引用符号的定义,就输出一条错误信息并终止。
另一方面,对全局符号的解析,经常会面临多个目标文件可能会定义相同名字的全局符号。这种情况下,链接器必须要么标志一个错误,要么以某种方法选出一个定义并抛弃其他定义。
# 多重定义的全局符号解析
链接器的输入是一组可重定位目标模块。每个模块定义一组符号,有些是局部符号(只对定义该符号的模块可见),有些是全局符号(对其他模块也可见)。如果多个模块定义同名的全局符号,该如何进行取舍?
Linux 编译系统采用如下的方法解决多重定义的全局符号解析:
在编译时,编译器想汇编器输出每个全局符号,或者是强(strong)或者是弱(weak),而汇编器把这个信息隐含地编码在可重定位目标文件的符号表中。
根据强弱符号的定义,Linux 链接器使用下面的规则来处理多重定义的符号名:
- 规则 1:不允许有多个同名的强符号。
- 规则 2:如果有一个强符号和多个弱符号同名,则选择强符号。
- 规则 3:如果有多个弱符号同名,则从这些弱符号中任意选择一个。
另一方面,由于允许一个符号定义在多个文件中,所以可能会导致一个问题:如果一个弱符号定义在多个目标文件中,而它们的类型不同,怎么办?这种情况主要有三种:
- 情况 1:两个或两个以上的强符号类型不一致。
- 情况 2:有一个强符号,其他都是弱符号,出现类型不一致。
- 情况 3:两个或两个以上弱符号类型不一致。
其中,情况 1 由于多个强符号定义本身就是非法的,所以链接器就会报错。对于后两种情况,编译器和链接器采用一种叫 COMMON 块(Common Block ) 的机制来处理。其过程如下:
首先,编译器将未初始化的全局变量定义为弱符号处理。对于情况 3,最终链接时选择最大的类型。对于情况 2,最终输出结果中的符号所占空间与强符号相同,如果链接过程中有弱符号大于强符号,链接器会发出警告。
# 重定位
事实上,重定位过程也伴随着符号的解析过程。链接的前两步完成之后,链接器就已经确定所有符号的虚拟地址了,那么链接器就可以根据符号的地址对每个需要重定位的指令进行地址修正。
那么链接器如何知道哪些指令是要被调整的呢?事实上,我们前面提到的 ELF 文件中的 重定位表(Relocation Table) 专门用来保存这些与重定位相关的信息。
对于可重定位的 ELF 文件来说,它必须包含重定位表,用来描述如何修改相应的节的内容。对于每个要被重定位的 ELF 节都有一个对应的重定位表。如果 .text 节需要被重定位,则会有一个相对应叫 .rel.text 的节保存了代码节的重定位表;如果 .data 节需要被重定位,则会有一个相对应的 .rel.tdata 的节保存了数据节的重定位表。
我们可以使用 objdump 工具来查看目标文件中的重定位表:
$ objdump -r a.o
a.o: file format elf64-x86-64
RELOCATION RECORDS FOR [.text]:
OFFSET TYPE VALUE
0000000000000023 R_X86_64_32 share
0000000000000030 R_X86_64_PC32 swap-0x0000000000000004
0000000000000049 R_X86_64_PC32 __stack_chk_fail-0x0000000000000004
RELOCATION RECORDS FOR [.eh_frame]:
OFFSET TYPE VALUE
0000000000000020 R_X86_64_PC32 .text
我们可以看到每个要被重定位的地方是一个 重定位入口(Relocation Entry)。利用数据结构成员包含的信息,即可完成重定位。
# 静态链接
事实上,静态链接的过程就是上文所描述的过程。在 Linux 中,静态链接器(static linker) ld 以一组可重定位目标文件和命令行参数作为输入,生成一个完全链接的、可以加载和运行的可执行目标文件作为输出。输入的可重定位目标文件由各种不同的节组成,每一节都是一个连续的字节序列。
# 动态链接
静态链接使得进行模块化开发,大大提供了程序的开发效率。随着,程序规模的扩大,静态链接的诸多缺点也逐渐暴露出来,如:浪费内存和磁盘空间、模块更新困难等。在静态链接中,C 语言静态库是很典型的浪费空间的例子。关于模块更新,静态链接的程序有任何更新,都必须重新编译链接,用户则需要重新下载安装该程序。
解决空间浪费和更新困难最简单的方法便是将程序的模块相互分割开来,形成独立文件。简而言之,就是不对那些组成程序的目标文件进行链接,而是等到程序要运行时才进行链接。
# 动态链接的基本实现
动态链接涉及运行时的链接以及多个文件的装载,必需要有操作系统的支持。因为动态链接的情况下,进程的虚拟地址空间的分布会比静态链接情况下更为复杂,还有一些存储管理、内存共享、进程线程等机制在动态链接下也会有一些微妙的变化。
目前,主流操作系统都支持动态链接。在 Linux 中,ELF 动态链接文件被称为 动态共享对象(DSO,Dynamic Shared Objects),一般以 .so 为后缀;在 Windows 中,动态链接文件被称为 动态链接库(Dynamic Linking Library),一般以 .dll 为后缀。
在 Linux 中,常用的 C 语言库的运行库 glibc,其动态链接形式的版本保留在 /lib 目录下,文件名为 libc.so 。整个系统只保留一份 C 语言动态链接文件 libc.so ,所有的 C 语言编写的、动态链接的程序都可以在运行时使用它。当程序被装载时,系统的动态链接器会将程序所需要的所有动态链接库装载到进程的地址空间,并将程序中所有未解析的符号绑定到相应的动态链接库中,并进行重定位。
# 动态链接程序运行时地址空间分布
对于静态链接的可执行文件来说,整个进程只有一个文件要被映射,即可执行文件。而对于动态链接,除了可执行文件,还有它所依赖的共享目标文件。
关于共享目标文件在内存中的地址分配,主要有两种解决方案,分别是:
- 静态共享库(Static Shared Library)(地址固定)
- 动态共享库(Dynamic Shared Libary)(地址不固定)
# 静态共享库
静态共享库的做法是将程序的各个模块统一交给操作系统进行管理,操作系统在某个特定的地址划分出一些地址块,为那些已知的模块预留足够的空间。因为这个地址对于不同的应用程序来说,都是固定的,所以称之为静态。
但是静态共享库的目标地址会导致地址冲突、升级等问题。
# 动态共享库
采用动态共享库的方式,也称为装载时重定位(Load Time Relocation)。其基本思路是:在链接时,对所有绝对地址的引用都不作重定位,而把这一步推迟到装载时再完成。一旦模块装载地址确定,即目标地址确定,那么系统就对程序中所有的绝对地址引用进行重定位。
但是这种方式也存在一些问题。比如,动态链接模块被装载映射至虚拟空间后,指令部分是在多个进程间共享的,由于装载时重定位的方法需要修改指令,所以没有办法做到同一份指令被多个进程共享,因为指令被重定位后对于每个进程来说都是不同的。
虽然,动态链接库中的代码是共享的,但是其中的可修改数据部分对于不同进程来说是由多个副本的。基于此,一种名为地址无关代码的技术被提出以克服这个问题。
# 地址无关代码
计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决。
地址无关代码(PIC,Position-independent Code) 技术完美阐释了上面这句名言,其基本原理是:把指令中那些需要被修改的部分分离出来,跟数据部分放在一起,这样指令部分就可以保持不变,而数据部分可以在每个进程中拥有一个副本。
共享对象模块中的地址引用按照是否为跨模块分为两类:模块内部引用、模块外部引用。按照不用的引用方式又可分为:指令引用、数据引用。以如下代码为例,可得出如下四种类型:
- 类型 1:模块内部的函数调用。
- 类型 2:模块内部的数据访问,如模块中定义的全局变量、静态变量。
- 类型 3:模块外部的函数调用。
- 类型 4:模块外部的数据访问,如其他模块中定义的全局变量。
static int a;
extern int b;
extern void ext();
void bar() {
a = 1; // 类型2:模块内部数据访问
b = 2; // 类型4:模块外部数据访问
}
void foo() {
bar(); // 类型1:模块内部函数调用
ext(); // 类型4:模块外部函数调用
}
# 类型 1 模块内部函数调用
由于被调用的函数与调用者都处于同一模块,它们之间的相对位置是固定的。对于现代的系统来说,模块内部的调用都可以是相对地址调用,或者是基于寄存器的相对调用,所以对于这种指令是不需要重定位的。
# 类型 2 模块内部数据访问
一个模块前面一般是若干个页的代码,后面紧跟着若干个页的数据,这些页之间的相对位置是固定的,即任何一条指令与它需要访问的模块内部数据之间的相对位置是固定的,所以只需要相对于当前指令加上固定的偏移量就可以访问模块内部数据了。
# 类型 3 模块间数据访问
模块间的数据访问比模块内部稍微麻烦一些,因为模块间的数据访问目标地址要等到装载时才决定。此时,动态链接需要使用代码无关地址技术,其基本思想是把地址相关的部分放到数据段。ELF 的实现方法是:在数据段中建立一个指向这些变量的指针数组,也称为全局偏移表(Global Offset Table,GOT),当代码需要引用该全局变量时,可以通过 GOT 中相对应的项间接引用。过程示意图如下所示:
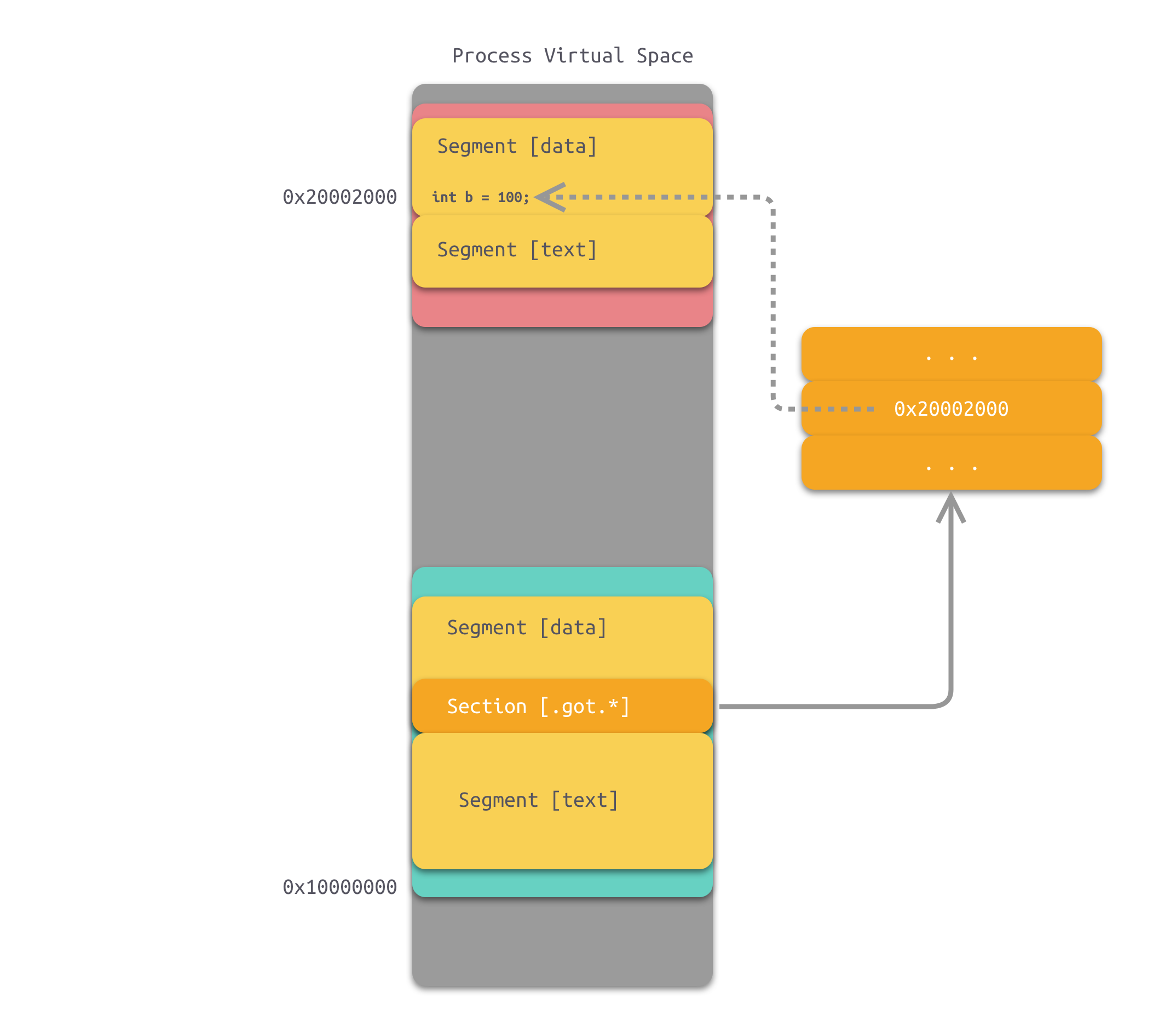
当指令中需要访问变量 b 时,程序会先找到 GOT,然后根据 GOT 中变量所对应的项找到变量的目标地址。每个变量都对应一个 4 字节的地址,链接器在装载模块时会查找每个变量所在的地址,然后填充 GOT 中的各个项,以确保每个指针所指向的地址正确。由于 GOT 本身是放在数据段的,所以它可以在模块装载时被修改,并且每个进程都可以有独立的副本,相互不受影响。
# 类型 4 模块间函数调用
对于模块间函数调用,同样可以采用类型 3 的方法来解决。与上面的类型有所不同的是,GOT 中响应的项保存的是目标函数的地址,当模块需要调用目标函数时,可以通过 GOT 中的项进行间接跳转。
# ELF 的装载过程
此处的内容来源于计算机那些事 (6)—— 可执行文件的装载与运行,仅作学习记录和备份用
当我们在 Linux 的 bash 中输入命令执行某个 ELF 可执行文件时,如下所示。
$ ./hello.out
那么,Linux 系统是如何装载该 ELF 文件并执行的呢?这个过程可以分为以下这些步骤:
- 创建新进程
- 检查可执行文件类型
- 搜索匹配装载处理过程
- 装载执行可执行文件
# 创建新进程
首先在用户层面,bash 进程会调用 fork() 系统调用创建一个新的进程。其次,新的进程通过调用 execve() 系统调用来执行指定的 ELF 文件。原先的 bash 进程继续返回并等待刚才启动的新进程结束,之后继续等待用户输入命令。
execve() 系统调用被定义在 unistd.h ,其原型如下所示。其中的三个参数分别对应被执行程序的 程序文件名、执行参数、环境变量。
int execve(const char *filename, char *const argv[], char *const envp[]);
# 检查可执行文件类型
当进入 execve() 系统调用之后,Linux 内核就开始进行真正的装载工作。在内核中, execve() 系统调用相应的入口是 sys_execve() 。 sys_execve() 进行一些参数的检查复制之后,调用 do_execve() 。 do_execve() 会首先查找被执行的文件,如果找到文件,则读取文件的前 128 个字节。
为什么要先读取文件的前 128 个字节?这是因为 Linux 支持的可执行文件不止 ELF 一种,还包括 a.out、Java 程序、以 #! 开头的脚本程序。 do_execve() 通过读取前 128 个字节来判断文件的格式。每种可执行文件格式的开头几个字节都是很特殊的,尤其是前 4 个字节,被称为 魔数(Magic Number)。比如:ELF 的可执行文件格式的头 4 个字节为 0x7F 、 e 、 l 、 f ;Java 的可执行文件格式的头 4 个字节为 c 、 a 、 f 、 e ;如果是解释型语言的脚本,则第一行通常是 #!/bin/sh 或 #!/user/bin/python ,其中 # 和 ! 构成了魔数,系统一旦判断到这两个字节,就对后面的字符串进行解析,以确定具体的解释程序的路径。
# 搜索匹配装载处理过程
当 do_execve() 读取了 128 个字节的文件头部之后,调用 search_binary_handle() 去搜索和匹配合适的可执行文件装载处理过程。Linux 中所有被支持的可执行文件格式都有相应的装载处理过程, search_binary_handler() 会通过判断头部的魔术确定文件的格式,并且调用相应的装载处理过程。常见的可执行程序及其装载处理过程的对应关系如下所示.
- ELF 可执行文件:
load_elf_binary() - a.out 可执行文件:
load_aout_binary() - 可执行脚本程序:
load_script()
# 装载执行可执行文件
以 ELF 的装载处理过程 load_elf_binary() 为例,其所包含的步骤如下图所示:
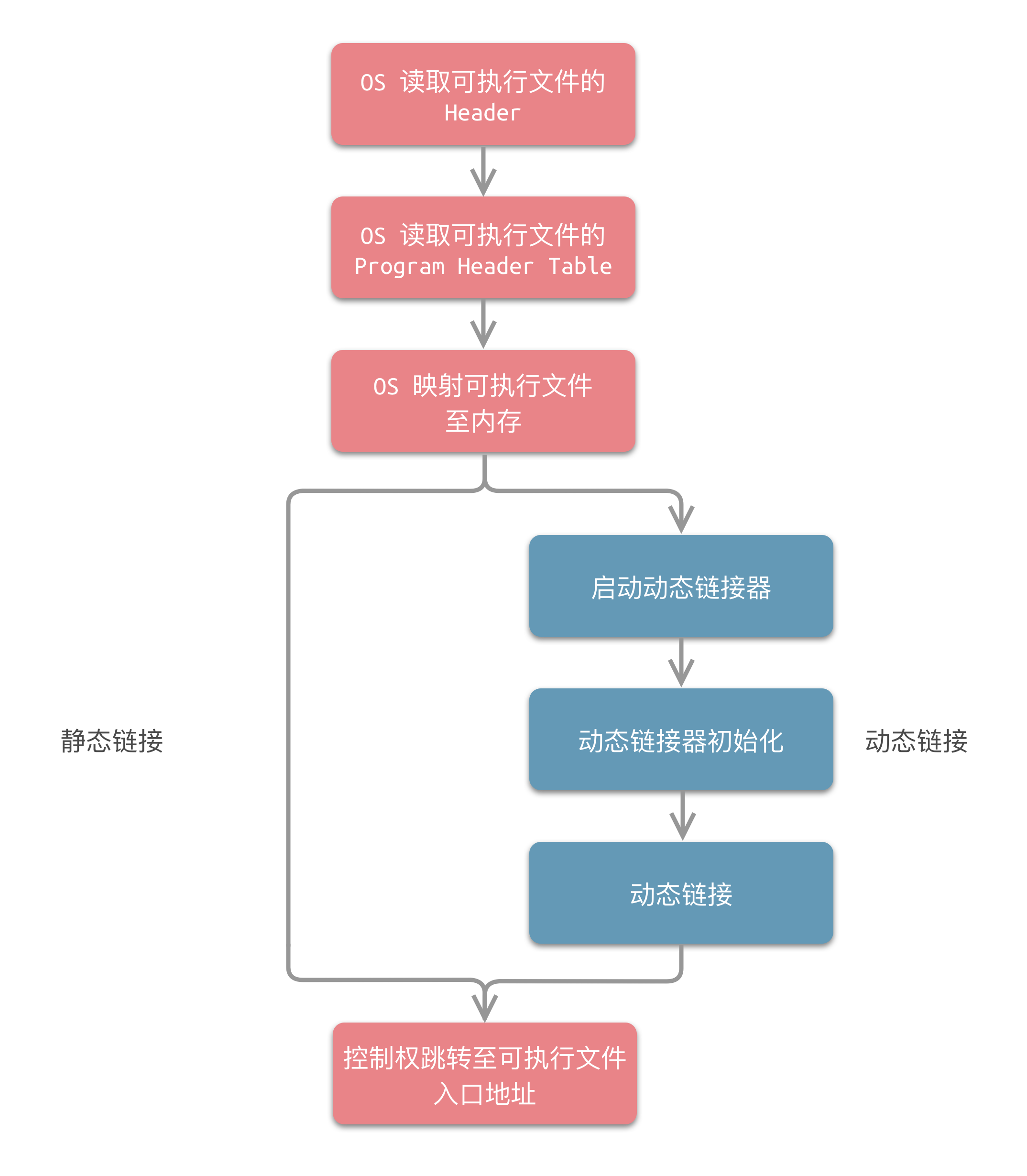
- 操作系统读取可执行文件 ELF 的
Header,检查文件的有效性。 - 操作系统读取可执行文件 ELF 的
Program Header Table中读取每个Segment的虚拟地址、文件地址、属性等。 - 操作系统根据
Program Header Table将可执行文件 ELF 映射至内存。 - 如果是静态链接的情况,则直接跳转至第 7 步;如果是动态链接的情况,操作系统将查找
.interp节,找到 动态链接器(Dynamic Linker) 的位置,并启动动态链接器。在 Linux 下,动态链接器ld.so是一个共享对象,操作系统同样通过映射的方式将它加载到进程的地址空间。操作系统在加载完后,将控制权交给动态链接器的入口。 - 动态链接器获得控制权后,开始执行一系列初始化操作。
- 动态链接器根据当前的环境参数,对可执行文件进行动态链接工作。
- 控制权被转交到可执行文件的入口地址,程序开始正式执行。
# TECHNICAL NOTE ON ELF LOADING
在 android-platform\bionic\linker\linker_phdr.cpp 中开头的这处注释也可以帮助我们快速理解 ELF 的加载过程
TECHNICAL NOTE ON ELF LOADING.
An ELF file’s program header table contains one or more PT_LOAD
segments, which corresponds to portions of the file that need to
be mapped into the process’ address space.
Each loadable segment has the following important properties:
p_offset -> segment file offset
p_filesz -> segment file size
p_memsz -> segment memory size (always >= p_filesz)
p_vaddr -> segment's virtual address
p_flags -> segment flags (e.g. readable, writable, executable)
p_align -> segment's in-memory and in-file alignment
We will ignore the p_paddr field of ElfW(Phdr) for now.
The loadable segments can be seen as a list of [p_vaddr … p_vaddr+p_memsz)
ranges of virtual addresses. A few rules apply:
-
the virtual address ranges should not overlap.
-
if a segment’s p_filesz is smaller than its p_memsz, the extra bytes
between them should always be initialized to 0. -
ranges do not necessarily start or end at page boundaries. Two distinct
segments can have their start and end on the same page. In this case, the
page inherits the mapping flags of the latter segment.
Finally, the real load addrs of each segment is not p_vaddr. Instead the
loader decides where to load the first segment, then will load all others
relative to the first one to respect the initial range layout.
For example, consider the following list:
[ offset:0, filesz:0x4000, memsz:0x4000, vaddr:0x30000 ],
[ offset:0x4000, filesz:0x2000, memsz:0x8000, vaddr:0x40000 ],
This corresponds to two segments that cover these virtual address ranges:
0x30000...0x34000
0x40000...0x48000
If the loader decides to load the first segment at address 0xa0000000
then the segments’ load address ranges will be:
0xa0030000...0xa0034000
0xa0040000...0xa0048000
In other words, all segments must be loaded at an address that has the same
constant offset from their p_vaddr value. This offset is computed as the
difference between the first segment’s load address, and its p_vaddr value.
However, in practice, segments do not start at page boundaries. Since we
can only memory-map at page boundaries, this means that the bias is
computed as:
load_bias = phdr0_load_address - PAGE_START(phdr0->p_vaddr)
(NOTE: The value must be used as a 32-bit unsigned integer, to deal with
possible wrap around UINT32_MAX for possible large p_vaddr values).
And that the phdr0_load_address must start at a page boundary, with
the segment’s real content starting at:
phdr0_load_address + PAGE_OFFSET(phdr0->p_vaddr)
Note that ELF requires the following condition to make the mmap()-ing work:
PAGE_OFFSET(phdr0->p_vaddr) == PAGE_OFFSET(phdr0->p_offset)
The load_bias must be added to any p_vaddr value read from the ELF file to
determine the corresponding memory address.
# ElfReader 类
//android-platform\bionic\linker\linker_phdr.h | |
class ElfReader { | |
public: | |
ElfReader(); | |
bool Read(const char* name, int fd, off64_t file_offset, off64_t file_size); | |
bool Load(address_space_params* address_space); | |
const char* name() const { return name_.c_str(); } | |
size_t phdr_count() const { return phdr_num_; } | |
ElfW(Addr) load_start() const { return reinterpret_cast<ElfW(Addr)>(load_start_); } | |
size_t load_size() const { return load_size_; } | |
ElfW(Addr) gap_start() const { return reinterpret_cast<ElfW(Addr)>(gap_start_); } | |
size_t gap_size() const { return gap_size_; } | |
ElfW(Addr) load_bias() const { return load_bias_; } | |
const ElfW(Phdr)* loaded_phdr() const { return loaded_phdr_; } | |
const ElfW(Dyn)* dynamic() const { return dynamic_; } | |
const char* get_string(ElfW(Word) index) const; | |
bool is_mapped_by_caller() const { return mapped_by_caller_; } | |
ElfW(Addr) entry_point() const { return header_.e_entry + load_bias_; } | |
private: | |
bool ReadElfHeader(); | |
bool VerifyElfHeader(); | |
bool ReadProgramHeaders(); | |
bool ReadSectionHeaders(); | |
bool ReadDynamicSection(); | |
bool ReserveAddressSpace(address_space_params* address_space); | |
bool LoadSegments(); | |
bool FindPhdr(); | |
bool FindGnuPropertySection(); | |
bool CheckPhdr(ElfW(Addr)); | |
bool CheckFileRange(ElfW(Addr) offset, size_t size, size_t alignment); | |
bool did_read_; | |
bool did_load_; | |
std::string name_; | |
int fd_; | |
off64_t file_offset_; | |
off64_t file_size_; | |
ElfW(Ehdr) header_; | |
size_t phdr_num_; | |
MappedFileFragment phdr_fragment_; | |
const ElfW(Phdr)* phdr_table_; | |
MappedFileFragment shdr_fragment_; | |
const ElfW(Shdr)* shdr_table_; | |
size_t shdr_num_; | |
MappedFileFragment dynamic_fragment_; | |
const ElfW(Dyn)* dynamic_; | |
MappedFileFragment strtab_fragment_; | |
const char* strtab_; | |
size_t strtab_size_; | |
// First page of reserved address space. | |
void* load_start_; | |
// Size in bytes of reserved address space. | |
size_t load_size_; | |
// First page of inaccessible gap mapping reserved for this DSO. | |
void* gap_start_; | |
// Size in bytes of the gap mapping. | |
size_t gap_size_; | |
// Load bias. | |
ElfW(Addr) load_bias_; | |
// Loaded phdr. | |
const ElfW(Phdr)* loaded_phdr_; | |
// Is map owned by the caller | |
bool mapped_by_caller_; | |
// Only used by AArch64 at the moment. | |
GnuPropertySection note_gnu_property_ __unused; | |
}; |
# AOSP 中解析 Elf 示例
在 AOSP 中,调用 ElfReader 解析 so 的示例代码如下所示,传入的四个参数的含义如下所示
realpath:elf的路径fd_: 打开的elf的fd文件描述符file_offset_:elf文件指针的当前偏移,初始值为 0file_size:elf的文件大小
//android-platform\bionic\linker\linker.cpp | |
//LoadTask::read | |
bool read(const char* realpath, off64_t file_size) { | |
ElfReader& elf_reader = get_elf_reader(); | |
return elf_reader.Read(realpath, fd_, file_offset_, file_size); | |
} |
# ElfReader::Read
非常典型的 elf解析五件套 代码,经过上面对于 ELF 的详细分析,我们也不难理解这五个函数的功能了
//android-platform\bionic\linker\linker_phdr.cpp | |
bool ElfReader::Read(const char* name, int fd, off64_t file_offset, off64_t file_size) { | |
if (did_read_) { | |
return true; | |
} | |
name_ = name; | |
fd_ = fd; | |
file_offset_ = file_offset; | |
file_size_ = file_size; | |
if (ReadElfHeader() && | |
VerifyElfHeader() && | |
ReadProgramHeaders() && | |
ReadSectionHeaders() && | |
ReadDynamicSection()) { | |
did_read_ = true; | |
} | |
return did_read_; | |
} |
# ReadElfHeader
读取 ELF Header
//android-platform\bionic\linker\linker_phdr.cpp | |
bool ElfReader::ReadElfHeader() { | |
ssize_t rc = TEMP_FAILURE_RETRY(pread64(fd_, &header_, sizeof(header_), file_offset_)); | |
if (rc < 0) { | |
DL_ERR("can't read file \"%s\": %s", name_.c_str(), strerror(errno)); | |
return false; | |
} | |
if (rc != sizeof(header_)) { | |
DL_ERR("\"%s\" is too small to be an ELF executable: only found %zd bytes", name_.c_str(), | |
static_cast<size_t>(rc)); | |
return false; | |
} | |
return true; | |
} |
# VerifyElfHeader
判断是否是 ELF Header 的合法性
//android-platform\bionic\linker\linker_phdr.cpp | |
bool ElfReader::VerifyElfHeader() { | |
if (memcmp(header_.e_ident, ELFMAG, SELFMAG) != 0) { | |
DL_ERR("\"%s\" has bad ELF magic: %02x%02x%02x%02x", name_.c_str(), | |
header_.e_ident[0], header_.e_ident[1], header_.e_ident[2], header_.e_ident[3]); | |
return false; | |
} | |
// Try to give a clear diagnostic for ELF class mismatches, since they're | |
// an easy mistake to make during the 32-bit/64-bit transition period. | |
int elf_class = header_.e_ident[EI_CLASS]; | |
#if defined(__LP64__) | |
if (elf_class != ELFCLASS64) { | |
if (elf_class == ELFCLASS32) { | |
DL_ERR("\"%s\" is 32-bit instead of 64-bit", name_.c_str()); | |
} else { | |
DL_ERR("\"%s\" has unknown ELF class: %d", name_.c_str(), elf_class); | |
} | |
return false; | |
} | |
#else | |
if (elf_class != ELFCLASS32) { | |
if (elf_class == ELFCLASS64) { | |
DL_ERR("\"%s\" is 64-bit instead of 32-bit", name_.c_str()); | |
} else { | |
DL_ERR("\"%s\" has unknown ELF class: %d", name_.c_str(), elf_class); | |
} | |
return false; | |
} | |
#endif | |
if (header_.e_ident[EI_DATA] != ELFDATA2LSB) { | |
DL_ERR("\"%s\" not little-endian: %d", name_.c_str(), header_.e_ident[EI_DATA]); | |
return false; | |
} | |
if (header_.e_type != ET_DYN) { | |
DL_ERR("\"%s\" has unexpected e_type: %d", name_.c_str(), header_.e_type); | |
return false; | |
} | |
if (header_.e_version != EV_CURRENT) { | |
DL_ERR("\"%s\" has unexpected e_version: %d", name_.c_str(), header_.e_version); | |
return false; | |
} | |
if (header_.e_machine != GetTargetElfMachine()) { | |
DL_ERR("\"%s\" is for %s (%d) instead of %s (%d)", | |
name_.c_str(), | |
EM_to_string(header_.e_machine), header_.e_machine, | |
EM_to_string(GetTargetElfMachine()), GetTargetElfMachine()); | |
return false; | |
} | |
if (header_.e_shentsize != sizeof(ElfW(Shdr))) { | |
// Fail if app is targeting Android O or above | |
if (get_application_target_sdk_version() >= 26) { | |
DL_ERR_AND_LOG("\"%s\" has unsupported e_shentsize: 0x%x (expected 0x%zx)", | |
name_.c_str(), header_.e_shentsize, sizeof(ElfW(Shdr))); | |
return false; | |
} | |
DL_WARN_documented_change(26, | |
"invalid-elf-header_section-headers-enforced-for-api-level-26", | |
"\"%s\" has unsupported e_shentsize 0x%x (expected 0x%zx)", | |
name_.c_str(), header_.e_shentsize, sizeof(ElfW(Shdr))); | |
add_dlwarning(name_.c_str(), "has invalid ELF header"); | |
} | |
if (header_.e_shstrndx == 0) { | |
// Fail if app is targeting Android O or above | |
if (get_application_target_sdk_version() >= 26) { | |
DL_ERR_AND_LOG("\"%s\" has invalid e_shstrndx", name_.c_str()); | |
return false; | |
} | |
DL_WARN_documented_change(26, | |
"invalid-elf-header_section-headers-enforced-for-api-level-26", | |
"\"%s\" has invalid e_shstrndx", name_.c_str()); | |
add_dlwarning(name_.c_str(), "has invalid ELF header"); | |
} | |
return true; | |
} |
# ReadProgramHeaders
读取 Program Header
//android-platform\bionic\linker\linker_phdr.cpp | |
// Loads the program header table from an ELF file into a read-only private | |
// anonymous mmap-ed block. | |
bool ElfReader::ReadProgramHeaders() { | |
phdr_num_ = header_.e_phnum; | |
// Like the kernel, we only accept program header tables that | |
// are smaller than 64KiB. | |
if (phdr_num_ < 1 || phdr_num_ > 65536/sizeof(ElfW(Phdr))) { | |
DL_ERR("\"%s\" has invalid e_phnum: %zd", name_.c_str(), phdr_num_); | |
return false; | |
} | |
// Boundary checks | |
size_t size = phdr_num_ * sizeof(ElfW(Phdr)); | |
if (!CheckFileRange(header_.e_phoff, size, alignof(ElfW(Phdr)))) { | |
DL_ERR_AND_LOG("\"%s\" has invalid phdr offset/size: %zu/%zu", | |
name_.c_str(), | |
static_cast<size_t>(header_.e_phoff), | |
size); | |
return false; | |
} | |
if (!phdr_fragment_.Map(fd_, file_offset_, header_.e_phoff, size)) { | |
DL_ERR("\"%s\" phdr mmap failed: %s", name_.c_str(), strerror(errno)); | |
return false; | |
} | |
phdr_table_ = static_cast<ElfW(Phdr)*>(phdr_fragment_.data()); | |
return true; | |
} |
# ReadSectionHeaders
读取 Section Header
//android-platform\bionic\linker\linker_phdr.cpp | |
bool ElfReader::ReadSectionHeaders() { | |
shdr_num_ = header_.e_shnum; | |
if (shdr_num_ == 0) { | |
DL_ERR_AND_LOG("\"%s\" has no section headers", name_.c_str()); | |
return false; | |
} | |
size_t size = shdr_num_ * sizeof(ElfW(Shdr)); | |
if (!CheckFileRange(header_.e_shoff, size, alignof(const ElfW(Shdr)))) { | |
DL_ERR_AND_LOG("\"%s\" has invalid shdr offset/size: %zu/%zu", | |
name_.c_str(), | |
static_cast<size_t>(header_.e_shoff), | |
size); | |
return false; | |
} | |
if (!shdr_fragment_.Map(fd_, file_offset_, header_.e_shoff, size)) { | |
DL_ERR("\"%s\" shdr mmap failed: %s", name_.c_str(), strerror(errno)); | |
return false; | |
} | |
shdr_table_ = static_cast<const ElfW(Shdr)*>(shdr_fragment_.data()); | |
return true; | |
} |
# ReadDynamicSection
读取 Dynamic Section
//android-platform\bionic\linker\linker_phdr.cpp | |
bool ElfReader::ReadDynamicSection() { | |
// 1. Find .dynamic section (in section headers) | |
const ElfW(Shdr)* dynamic_shdr = nullptr; | |
for (size_t i = 0; i < shdr_num_; ++i) { | |
if (shdr_table_[i].sh_type == SHT_DYNAMIC) { | |
dynamic_shdr = &shdr_table_ [i]; | |
break; | |
} | |
} | |
if (dynamic_shdr == nullptr) { | |
DL_ERR_AND_LOG("\"%s\" .dynamic section header was not found", name_.c_str()); | |
return false; | |
} | |
// Make sure dynamic_shdr offset and size matches PT_DYNAMIC phdr | |
size_t pt_dynamic_offset = 0; | |
size_t pt_dynamic_filesz = 0; | |
for (size_t i = 0; i < phdr_num_; ++i) { | |
const ElfW(Phdr)* phdr = &phdr_table_[i]; | |
if (phdr->p_type == PT_DYNAMIC) { | |
pt_dynamic_offset = phdr->p_offset; | |
pt_dynamic_filesz = phdr->p_filesz; | |
} | |
} | |
if (pt_dynamic_offset != dynamic_shdr->sh_offset) { | |
if (get_application_target_sdk_version() >= 26) { | |
DL_ERR_AND_LOG("\"%s\" .dynamic section has invalid offset: 0x%zx, " | |
"expected to match PT_DYNAMIC offset: 0x%zx", | |
name_.c_str(), | |
static_cast<size_t>(dynamic_shdr->sh_offset), | |
pt_dynamic_offset); | |
return false; | |
} | |
DL_WARN_documented_change(26, | |
"invalid-elf-header_section-headers-enforced-for-api-level-26", | |
"\"%s\" .dynamic section has invalid offset: 0x%zx " | |
"(expected to match PT_DYNAMIC offset 0x%zx)", | |
name_.c_str(), | |
static_cast<size_t>(dynamic_shdr->sh_offset), | |
pt_dynamic_offset); | |
add_dlwarning(name_.c_str(), "invalid .dynamic section"); | |
} | |
if (pt_dynamic_filesz != dynamic_shdr->sh_size) { | |
if (get_application_target_sdk_version() >= 26) { | |
DL_ERR_AND_LOG("\"%s\" .dynamic section has invalid size: 0x%zx, " | |
"expected to match PT_DYNAMIC filesz: 0x%zx", | |
name_.c_str(), | |
static_cast<size_t>(dynamic_shdr->sh_size), | |
pt_dynamic_filesz); | |
return false; | |
} | |
DL_WARN_documented_change(26, | |
"invalid-elf-header_section-headers-enforced-for-api-level-26", | |
"\"%s\" .dynamic section has invalid size: 0x%zx " | |
"(expected to match PT_DYNAMIC filesz 0x%zx)", | |
name_.c_str(), | |
static_cast<size_t>(dynamic_shdr->sh_size), | |
pt_dynamic_filesz); | |
add_dlwarning(name_.c_str(), "invalid .dynamic section"); | |
} | |
if (dynamic_shdr->sh_link >= shdr_num_) { | |
DL_ERR_AND_LOG("\"%s\" .dynamic section has invalid sh_link: %d", | |
name_.c_str(), | |
dynamic_shdr->sh_link); | |
return false; | |
} | |
const ElfW(Shdr)* strtab_shdr = &shdr_table_[dynamic_shdr->sh_link]; | |
if (strtab_shdr->sh_type != SHT_STRTAB) { | |
DL_ERR_AND_LOG("\"%s\" .dynamic section has invalid link(%d) sh_type: %d (expected SHT_STRTAB)", | |
name_.c_str(), dynamic_shdr->sh_link, strtab_shdr->sh_type); | |
return false; | |
} | |
if (!CheckFileRange(dynamic_shdr->sh_offset, dynamic_shdr->sh_size, alignof(const ElfW(Dyn)))) { | |
DL_ERR_AND_LOG("\"%s\" has invalid offset/size of .dynamic section", name_.c_str()); | |
return false; | |
} | |
if (!dynamic_fragment_.Map(fd_, file_offset_, dynamic_shdr->sh_offset, dynamic_shdr->sh_size)) { | |
DL_ERR("\"%s\" dynamic section mmap failed: %s", name_.c_str(), strerror(errno)); | |
return false; | |
} | |
dynamic_ = static_cast<const ElfW(Dyn)*>(dynamic_fragment_.data()); | |
if (!CheckFileRange(strtab_shdr->sh_offset, strtab_shdr->sh_size, alignof(const char))) { | |
DL_ERR_AND_LOG("\"%s\" has invalid offset/size of the .strtab section linked from .dynamic section", | |
name_.c_str()); | |
return false; | |
} | |
if (!strtab_fragment_.Map(fd_, file_offset_, strtab_shdr->sh_offset, strtab_shdr->sh_size)) { | |
DL_ERR("\"%s\" strtab section mmap failed: %s", name_.c_str(), strerror(errno)); | |
return false; | |
} | |
strtab_ = static_cast<const char*>(strtab_fragment_.data()); | |
strtab_size_ = strtab_fragment_.size(); | |
return true; | |
} |
# 参考资料
- 深入浅出 ELF
- https://ctf-wiki.org/executable/elf
- 计算机那些事 (4)——ELF 文件结构
- 计算机那些事 (5)—— 链接、静态链接、动态链接
- 计算机那些事 (6)—— 可执行文件的装载与运行