# 前言
已经是四月底了,但是却突然发现这一整个月都没有在博客写些什么,感觉又是在不明所以中度过了,想看的 magisk , frida 源码没有看完,想做的小夏的 live2d 也迟迟没有动工,下个月努努力,多学点,多做点,加油加油
总觉得自己还是要写下点什么才好,恰好这周听闻有个 d3ctf, 于是便想来看看逆向题,去学习一下新知识开拓视野,同时也为了度过一段充实的周末时光
回想去年的 d3ctf, 感觉那时的自己有太多不了解的地方了,于是乎情理之中的也是一题都没做出来了,复现的题目的计划在我的 todolist 里面躺了很长一段时间,然而不知不觉间变成了 undo, 最后到现在的 forget do,never do
同时我也想来看看一下这一年的自己有了什么变化,感觉现在可以称自己是一位入门逆向工程师了吧哈哈哈,总共五道逆向题做好了三题,可惜周日因为要调休的缘故 (谁发明的调休?!) 便没有再继续看题了,题目挺不错的,不过要是可以有安卓题的话我应该会有百分之三百的精气神去做吧 ^.^
翻了翻自己过去写的 ctf 文章,那也仅仅是 wp 出个 flag 而已,但是 flag 不是题目的终点,二进制文件中蕴藏的技巧,手法才是真正值得总结一篇文章的地方,我可不希望自己写的文章在未来连我自己都不愿重新翻看 (●ˇ∀ˇ●)
题目附件点这里下载~
# forest
很好的一道题,将 MSVC 的 SEH 异常处理使用的十分巧妙,同时点和图的思想也在这题有了充分的体现,在做这题的时候有一个失败的解法,不过我感觉很有意思所以也在这里记录下来啦
这里你会看到地址都是 61 开头,那时因为用 od 的时候里面的基址就是 0x610000 , 所以当时为了和 ida 中对应起来我也改成了 61 开头,不过最后 od 还是没有排上用场全靠 ida 动态调试啦
这里通过主动设置 int 3 断点触发 0x80000003 断点异常进入 sub_611A00
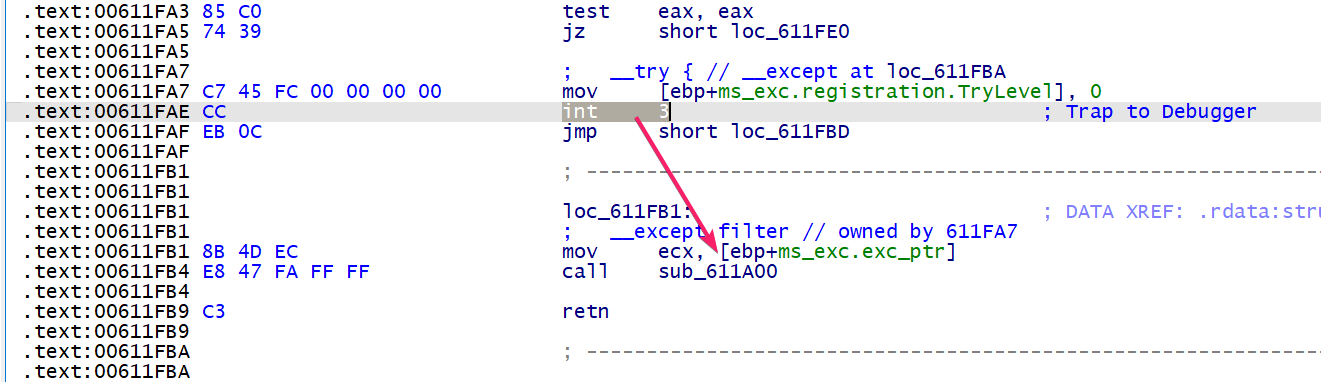
在 sub_611A00 中,对异常码进行判断,这里可以重定义 this 参数类型为 _EXCEPTION_POINTERS , 这样看起来更方便些,感觉是一个小小的突破口哦
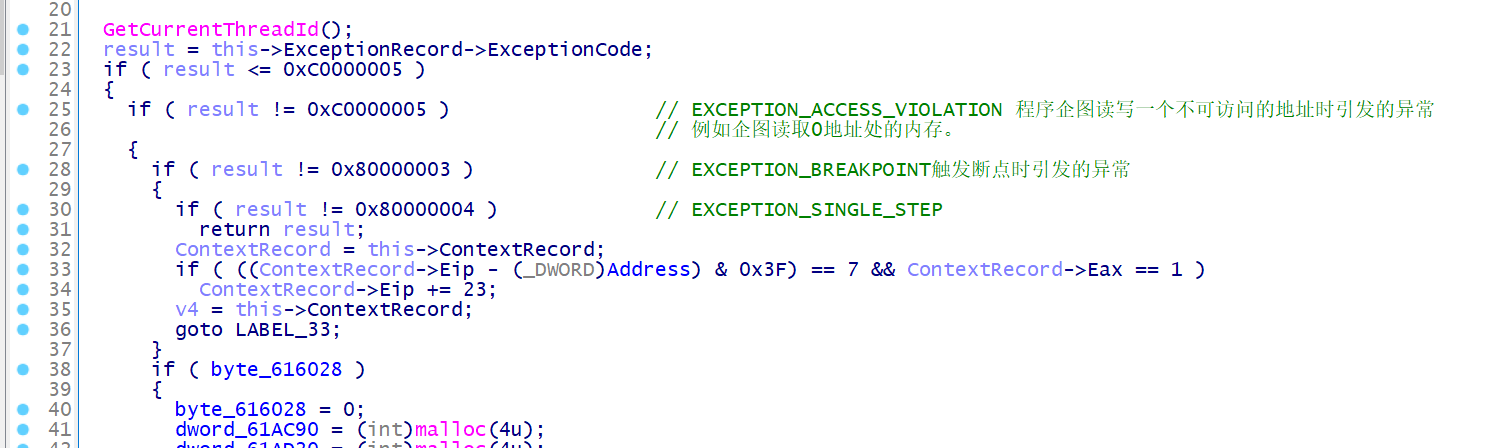
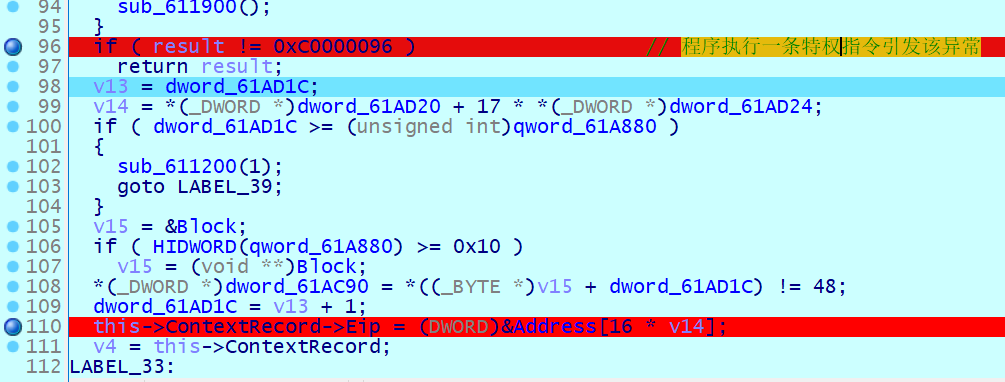
首次触发断点异常,解密由 VirtualProtect 分配的内存地址的值,并设置 byte_616028 标志为 0, 下一次触发断点异常将视为 flag 错误,进程退出
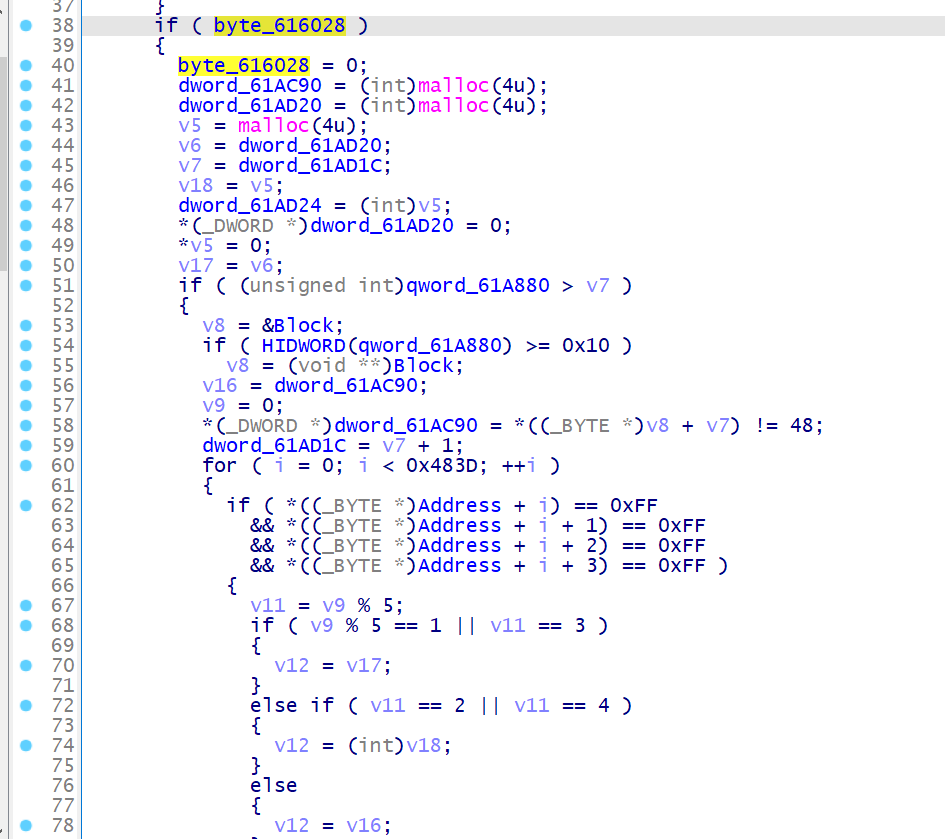
解密完成后设置 EIP, 并通过 this->ContextRecord->EFlags |= 0x100 设置单步调试模式,使标志寄存器第 8 位 TF 为 1
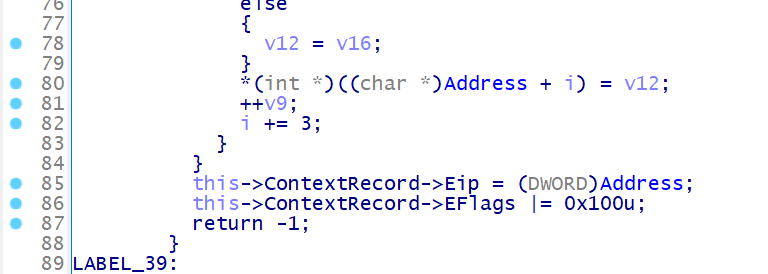
随后程序会通过调用 cli 特权指令实现 shellcode 的跳转
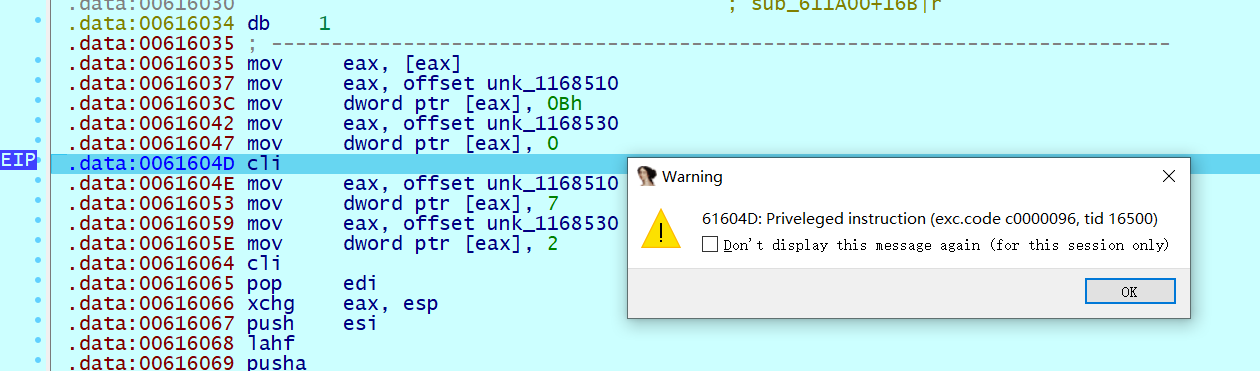
int 2Dh 表示 flag 错误
# [失败] frida 侧信道
说的高大上一点叫侧信道,实际上就是爆破哈哈哈,我调试的时候发现每一次输入的 flag 不一样,调用 cli 特权指令触发 0xC0000096 的次数也不一样,所以我就在想,要是我可以一位一位的爆破,通过在处理 0xC0000096 异常的地方下断点统计调用次数,然后然调用最多的那个字符作为这一位的 flag, 那不就得到最后的 flag 了嘛~
所以这回用上了我的老伙计 frida, 想要通过 frida 实现爆破,那么需要使用 frida 的 python 脚本,同时输入也不能再是 console.log , 而是需要使用 send 将结果返回到 python 中去做处理
function my_hook() { | |
var module = Process.findModuleByName(exe_name); | |
Interceptor.attach(module.base.add(0x1BDE), | |
{ | |
onEnter: function (args) { | |
if(this.context.eax.compare(0xC0000096)===0){ | |
count=count+1 | |
//console.log(this.context.eax) | |
//console.log(ptr(module.base.add(0xAD20).readS32()).readS32().toString(16)) | |
//console.log(ptr(module.base.add(0xAD24).readS32()).readS32().toString(16)) | |
send(count) | |
} | |
}, | |
onLeave: function (retval) { | |
} | |
} | |
); | |
} | |
// d3ctf{01234567890123456} | |
setImmediate(my_hook); |
这个 python 的代码虽然很简单但是也巧妙,嘻嘻
import os | |
import subprocess | |
import frida | |
import string | |
#d3ctf{0ut00431101002001} | |
def on_message(message, data): | |
global max_count,max_ch,current_ch | |
if message['type'] == 'send': | |
if not max_count: | |
max_count = int(message['payload']) | |
max_ch = current_ch | |
elif int(message['payload'])>max_count: | |
max_count = message['payload'] | |
max_ch = current_ch | |
elif int(message['payload'])==max_count: | |
print(f"NOTE! {max_ch} and {current_ch} have the same max_count {max_count}") | |
elif message['type'] == "error": | |
print(message["description"]) | |
print(message["stack"]) | |
print(message["fileName"], "line:", message["lineNumber"], "colum:", message["columnNumber"]) | |
jscode = open("trace_forest.js","rb").read().decode() | |
t_flag = list("d3ctf{01234567890123456}") | |
for i in range(6,23): | |
max_count, max_ch = None,None | |
break_flag = 0 | |
for c in string.printable: | |
current_ch = c | |
t_flag[i] = c | |
process = subprocess.Popen("forest.exe", | |
stdin=subprocess.PIPE, | |
stdout=subprocess.PIPE, | |
stderr=subprocess.PIPE, | |
universal_newlines=True) | |
session = frida.attach("forest.exe") | |
script = session.create_script(jscode) | |
script.on('message', on_message) | |
script.load() | |
process.stdin.write(''.join(t_flag)) | |
output, error = process.communicate() | |
process.terminate() | |
t_flag[i] = max_ch | |
print(f"{''.join(t_flag)}, max: {max_count}") |
但是可惜的是程序跑完出来了这个 d3ctf{0ut00431101002001} , 虽然是错的但是回显不一样了 ^.^
这何尝不是一种胜利~不过换个方法咯
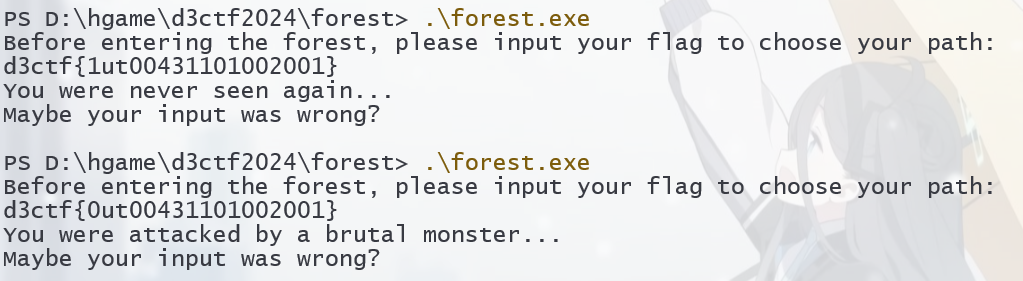
# [成功] 图 点 路径
如果想要产生正确的回显,必须触发 0xC0000005 异常

输入的字符串将会被全部转换为二进制的形式,每执行 cli 特权指令触发 0xC0000096 异常后都会读取一位

如果为 0, 则下一次触发 0x80000004 单步调试异常且当前指令的偏移逻辑 &0x3F 等于 7 时,将会让当前的 Eip 加上 23
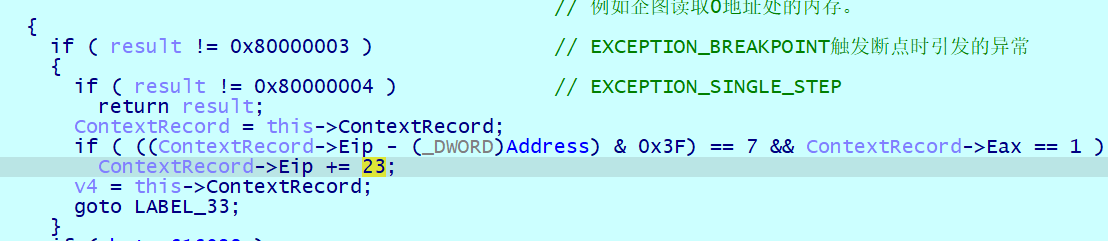
进入下一个块的位置由 unk_EAA720 和 unk_EA8658 进行控制,算法为 (unk_EAA720+unk_EA8658+(unk_EA8658<<4))<<6
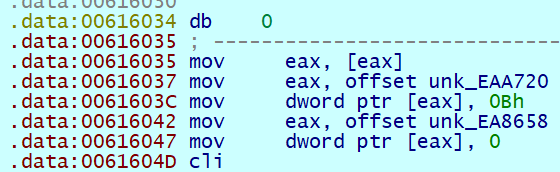
观察后发现这明显就是一个图呀,所以可以用 idapython 找到图的所有边
# d3ctf{0ut00431101002001} | |
import idautils | |
import idc | |
import ida_bytes | |
base = 0x616035 | |
pattern = ["B8 FF FF FF FF C7 00 ?? 00 00 00 B8 FF FF FF FF C7 00 ?? 00 00 00 FA"] | |
pl = [] # point list | |
for i in range(len(pattern)): | |
cur_addr = 0x616035 | |
end_addr = 0x616035 + 0x483D | |
while cur_addr < end_addr: | |
cur_addr = idc.find_binary(cur_addr, idc.SEARCH_DOWN, pattern[i]) | |
if cur_addr == idc.BADADDR: | |
break | |
else: | |
a = ida_bytes.get_byte(cur_addr + 7) | |
b = ida_bytes.get_byte(cur_addr + 18) | |
pl.append({ | |
"cur": cur_addr, | |
"off": (a + b + (b << 4)) << 6, | |
"s": 0 | |
}) | |
cur_addr = idc.next_head(cur_addr) | |
pattern = ["8B 00"] | |
for i in range(len(pattern)): | |
cur_addr = 0x616035 | |
end_addr = 0x616035 + 0x483D | |
while cur_addr < end_addr: | |
cur_addr = idc.find_binary(cur_addr, idc.SEARCH_DOWN, pattern[i]) | |
if cur_addr == idc.BADADDR: | |
break | |
else: | |
# if cur_addr-(base+5) &0x3F==7,eax->1, eip+23 | |
pl.append({ | |
"cur": cur_addr, | |
"off": cur_addr + 23 - base, | |
"s": 1 | |
}) | |
cur_addr = idc.next_head(cur_addr) | |
print(pl) |
然后打印一下没有对应端点的点,这里只是部分,实际上还有很多…
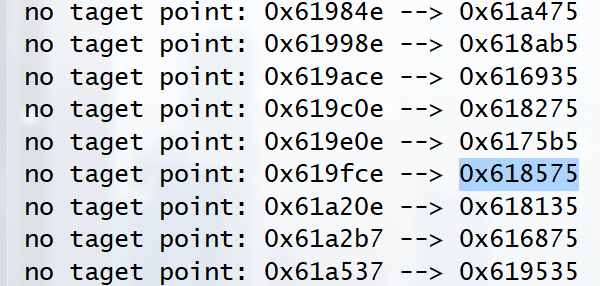
之后一个一个试过去,就有 flag 了 (为什么不用 for 循环尝试所有可能的点,因为用 for 循环 all_simple_paths 不出结果呜)
base = 0x616035 | |
pl = [...]# ida python 的结果 | |
import networkx as nx | |
G = nx.DiGraph() | |
for p in pl: | |
G.add_node(p["cur"]) | |
out_way = [] | |
for p in pl: | |
if not p["s"]: | |
if G.has_node(base+p["off"]): | |
G.add_edge(p["cur"],base+p["off"]) | |
else: | |
if base+p['off']>0x616035 + 0x483D: | |
print(f"find a way out: {hex(p['cur'])} --> {hex(base+p['off'])}") | |
G.add_node(base+p['off']) | |
G.add_edge(base,base+p['off']) | |
out_way.append(base+p['off']) | |
else: | |
print(f"no taget point: {hex(p['cur'])} --> {hex(base + p['off'])}") | |
out_way.append(base + p['off']) | |
else: | |
if G.has_node(p["cur"]+2+23): | |
G.add_edge(p["cur"],p["cur"]+2+23) | |
if G.has_node(p["cur"]+2): | |
G.add_edge(p["cur"], p["cur"] + 2) | |
else: | |
print("ERRR") | |
start = 0x616035 | |
tem = [] | |
out = 0x616c0e | |
for path in nx.all_simple_paths(G, source=start, target=out): | |
tem.append(path) | |
#print(tem) | |
#print(len(tem[0])) | |
pll = [] | |
for t in tem[0]: | |
for p in pl: | |
if p["cur"]==t: | |
#print(p["cur"],p["s"]) | |
pll.append(p) | |
break | |
start = True | |
flag="" | |
for p in range(len(pll)): | |
if p!=0: | |
if not pll[p]["s"]: | |
if pll[p]["cur"]-pll[p-1]["cur"]==2: | |
flag+="0" | |
else: | |
flag+="1" | |
for i in range(0,len(flag)//8): | |
print(chr(int(flag[8*i:8*i+8],2)),end='') |
# ezjunk
从整个程序的入口 start 函数开始分析,在执行 main 函数前,还会调用 sub_401CC0 函数
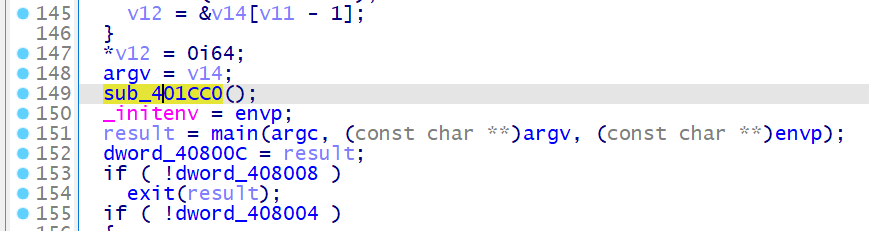
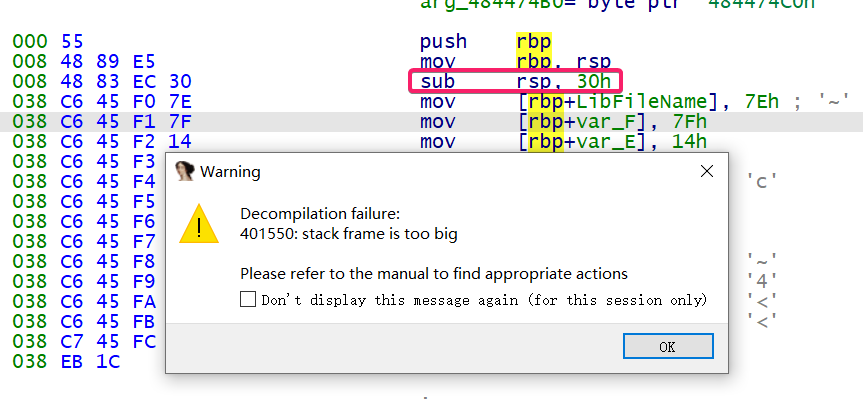
在这个函数中,会对 sub_401550 进行调用
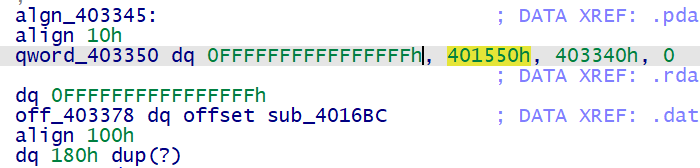
但是却没法直接反编译,既然是栈的问题,把 sub rsp, 30h nop 掉就好啦
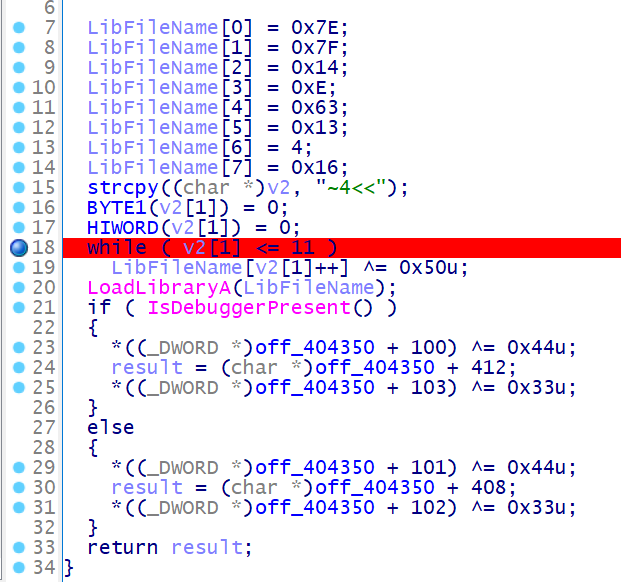
有个反调试,过一下就好了
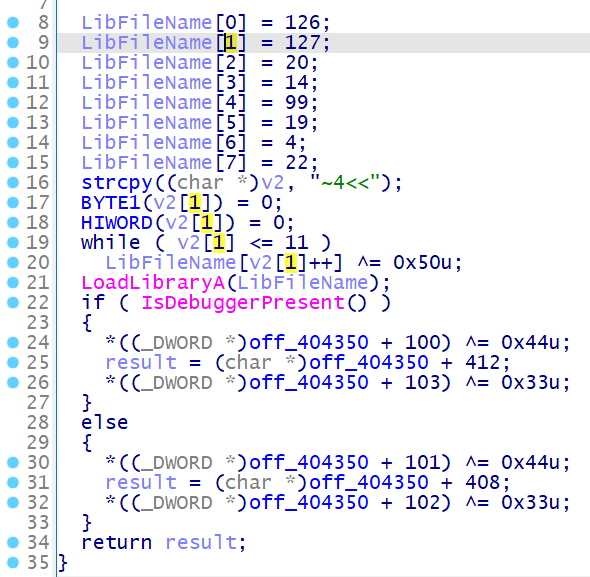
main 函数的花指令也很简单,去一下就看到逻辑啦
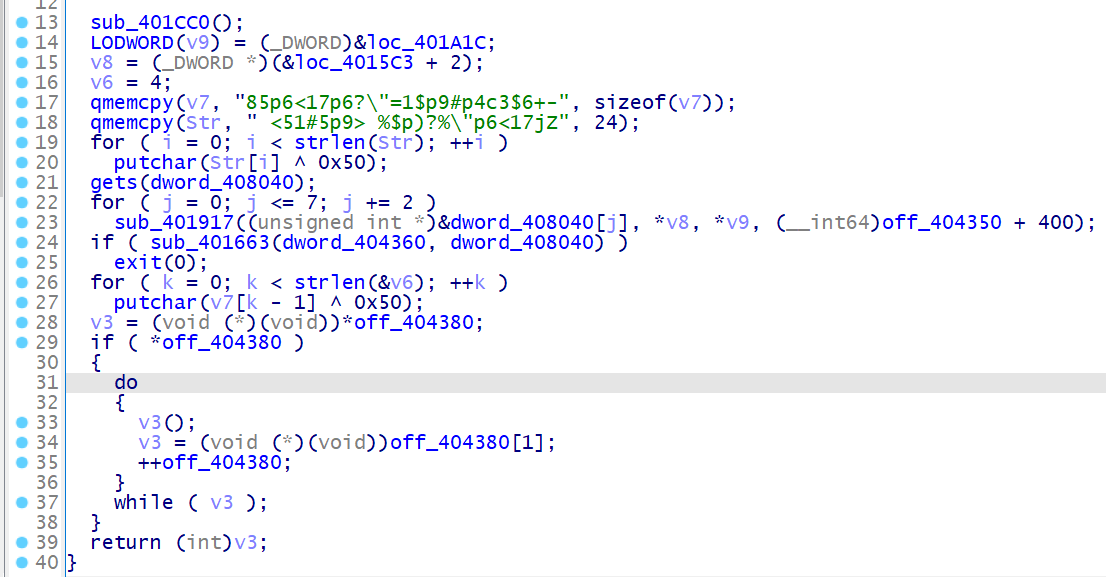
进到 sub_401917 里面,只是一个 tea 算法
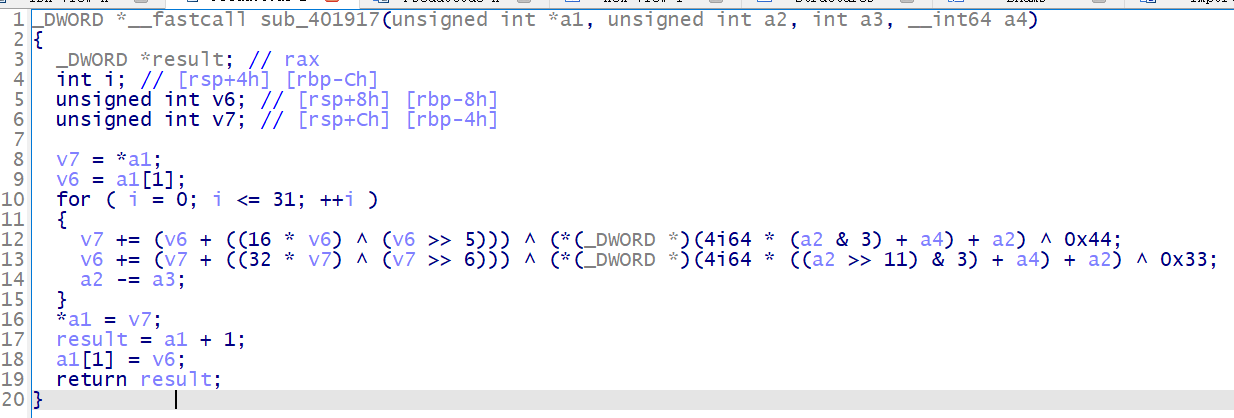
之后就是一个类似 crc 的算法
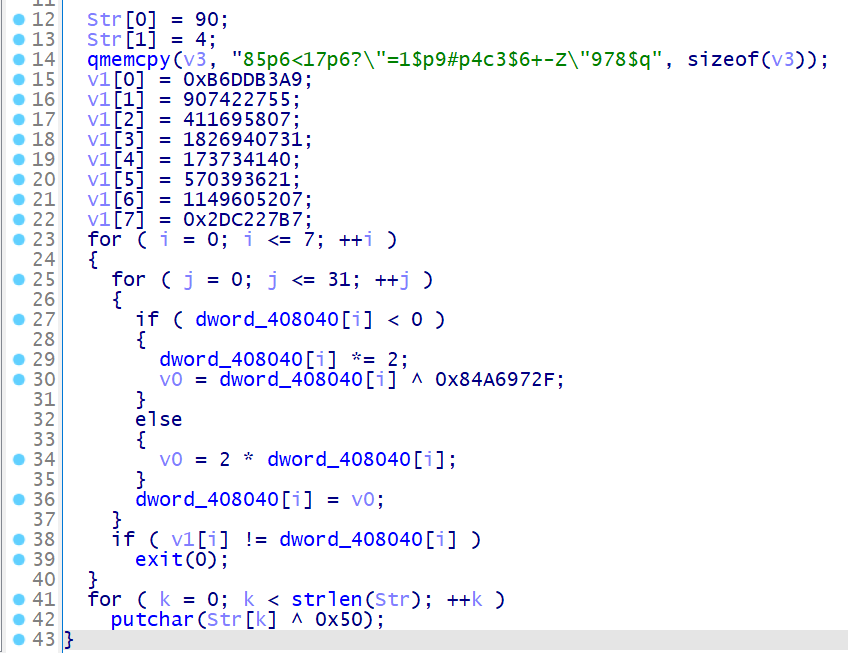
不过在调试的时候还是不能直接把花指令 nop 掉的,因为这里读取的是 loc401A1C 花指令的汇编,如果 nop 掉变成 90 的话,tea 的常数值会出错的
from ctypes import * | |
def encrypt(v, key): | |
v0, v1 = c_uint32(v[0]), c_uint32(v[1]) | |
delta = 0xff58f981 | |
total = c_uint32(0xE8017300) | |
for i in range(32): | |
v0.value += (((v1.value << 4) ^ (v1.value >> 5)) + v1.value) ^ (total.value + key[total.value & 3]) ^ 0x44 | |
v1.value += (((v0.value << 5) ^ (v0.value >> 6)) + v0.value) ^ ( | |
total.value + key[(total.value >> 11) & 3]) ^ 0x33 | |
total.value -= delta | |
return v0.value, v1.value | |
def decrypt(v, key): | |
v0, v1 = c_uint32(v[0]), c_uint32(v[1]) | |
delta = 0xff58f981 | |
total = c_uint32(0xE8017300 - 32 * delta) | |
for i in range(32): | |
total.value += delta | |
v1.value -= (((v0.value << 5) ^ (v0.value >> 6)) + v0.value) ^ ( | |
total.value + key[(total.value >> 11) & 3]) ^ 0x33 | |
v0.value -= (((v1.value << 4) ^ (v1.value >> 5)) + v1.value) ^ (total.value + key[total.value & 3]) ^ 0x44 | |
return v0.value, v1.value | |
# test | |
if __name__ == "__main__": | |
# 待加密的明文,两个 32 位整型,即 64bit 的明文数据 | |
# fakeflag{Is_there_anywhere_else} | |
# value = [0x5406CBB1, 0xA4A41EA2, 0x34489AC5, 0x53D68797, 0xB8E0C06F, 0x0259F2DB, 0x52E38D82, 0x595D5E1D] | |
value = [0xB6DDB3A9, 0x36162C23, 0x1889FABF, 0x6CE4E73B, 0x0A5AF8FC, 0x21FF8415, 0x44859557, 0x2DC227B7] | |
value = [c_uint(v) for v in value] | |
for i in range(len(value)): | |
for _ in range(32): | |
if value[i].value&1: | |
value[i] = c_uint(((value[i].value ^ 0x84A6972F)//2) | 0x80000000)#2086826726 | |
else: | |
value[i] = c_uint((value[i].value//2)) | |
value = [v.value for v in value] | |
#for v in value: | |
#print(hex(v)) | |
# value = [] | |
# 四个 key,每个是 32bit,即密钥长度为 128bit | |
key = [0x00005454, 0x00004602, 0x00004477, 0x00005E5E] | |
v = [0, 0] | |
for i in range(len(value) // 2): | |
v[0], v[1] = value[2 * i], value[2 * i + 1] | |
res = decrypt(v, key) | |
print(f"{res[0].to_bytes(4, 'little').decode()}{res[1].to_bytes(4, 'little').decode()}", end='') |
# RandomVM
VM 题型,不过算是比较方便的那种真正用到的指令不是很多,ida trace 在关键函数 trace 一下,不过有个 ptrace 反调试注意一下就好啦
syscall (0x65) ptrace 反调试,跳过这条指令就好了

比较重要的有这些函数
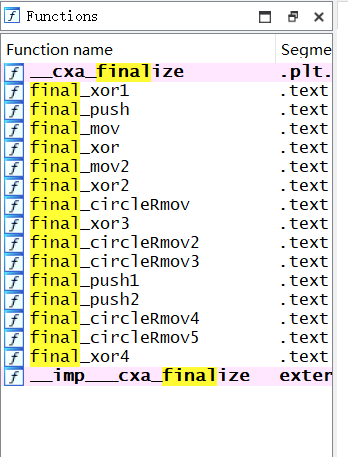
idapython trace 一下
#xor | |
import idc | |
import ida_bytes | |
import idaapi | |
ea = ida_bytes.get_byte(idaapi.get_imagebase()+0xB072) | |
ecx=idc.get_reg_value("ECX") | |
eax=idc.get_reg_value("EAX") | |
print(f"final[{ea}] = {hex(ecx)}^{hex(eax)} = {hex(ecx^eax)}") | |
#mov | |
import idc | |
import ida_bytes | |
import idaapi | |
ea = ida_bytes.get_byte(idaapi.get_imagebase()+0xB072) | |
eax=idc.get_reg_value("EAX") | |
print(f"final[{ea}] = {hex(eax)}") | |
#circleRmov | |
import idc | |
import ida_bytes | |
import idaapi | |
import ctypes | |
ea = ida_bytes.get_byte(idaapi.get_imagebase()+0xB072) | |
edx=idc.get_reg_value("EDX") | |
ecx=idc.get_reg_value("ECX")%8 | |
res = ctypes.c_uint8(edx) | |
if ecx!=0xffffffff: | |
res = ctypes.c_uint8((res.value>>ecx) | (res.value<<(8-ecx))) | |
else: | |
res = ctypes.c_uint8(0) | |
print(f"final[{ea}] = {hex(edx)}>>{ecx} | {hex(edx)}<<{8-ecx} = {hex(res.value)}") |
输入 0123456789ab 得到输出
final[0] = 0x0^0x30 = 0x30 | |
final[1] = 0x1 | |
final[1] = 0x30>>3 | 0x30<<5 = 0x6 | |
final[1] = 0x6^0x3 = 0x5 | |
final[1] = 0x5^0x31 = 0x34 | |
final[2] = 0x2 | |
final[2] = 0x31>>5 | 0x31<<3 = 0x89 | |
final[2] = 0x89^0x32 = 0xbb | |
final[3] = 0x3 | |
final[3] = 0x32>>6 | 0x32<<2 = 0xc8 | |
final[3] = 0xc8^0x33 = 0xfb | |
final[4] = 0x4 | |
final[4] = 0x33>>7 | 0x33<<1 = 0x66 | |
final[4] = 0x66^0x7 = 0x61 | |
final[4] = 0x61^0x34 = 0x55 | |
final[5] = 0x5 | |
final[5] = 0x34>>4 | 0x34<<4 = 0x43 | |
final[5] = 0x43^0x4 = 0x47 | |
final[5] = 0x47^0x35 = 0x72 | |
final[6] = 0x6 | |
final[6] = 0x35>>4 | 0x35<<4 = 0x53 | |
final[6] = 0x53^0x36 = 0x65 | |
final[7] = 0x7 | |
final[7] = 0x36>>7 | 0x36<<1 = 0x6c | |
final[7] = 0x6c^0x7 = 0x6b | |
final[7] = 0x6b^0x37 = 0x5c | |
final[8] = 0x8 | |
final[8] = 0x37>>7 | 0x37<<1 = 0x6e | |
final[8] = 0x6e^0x38 = 0x56 | |
final[9] = 0x9 | |
final[9] = 0x38>>2 | 0x38<<6 = 0xe | |
final[9] = 0xe^0x39 = 0x37 | |
final[10] = 0xa | |
final[10] = 0x39>>4 | 0x39<<4 = 0x93 | |
final[10] = 0x93^0x61 = 0xf2 | |
final[11] = 0xb | |
final[11] = 0x61>>4 | 0x61<<4 = 0x16 | |
final[11] = 0x16^0x62 = 0x74 | |
final[12] = 0xc | |
final[12] = 0x62>>7 | 0x62<<1 = 0xc4 | |
final[12] = 0xc4^0x7 = 0xc3 | |
final[2] = 0xbb^0x34 = 0x8f | |
final[3] = 0xfb^0x8f = 0x74 | |
final[4] = 0x55^0x74 = 0x21 | |
final[5] = 0x72^0x21 = 0x53 | |
final[6] = 0x65^0x53 = 0x36 | |
final[7] = 0x5c^0x36 = 0x6a | |
final[8] = 0x56^0x6a = 0x3c | |
final[9] = 0x37^0x3c = 0xb | |
final[10] = 0xf2^0xb = 0xf9 | |
final[11] = 0x74^0xf9 = 0x8d | |
final[12] = 0xc3^0x8d = 0x4e |
exp 如下
import ctypes | |
def circleR_rev(s, r): | |
res = ctypes.c_uint8(s) | |
res = ctypes.c_uint8((res.value << r) | (res.value >> (8 - r))) | |
return res.value | |
key = [0x9D, 0x6B, 0xA1, 0x02, 0xD7, 0xED, 0x40, 0xF6, 0x0E, 0xAE, 0x84, 0x19] | |
circle_R = [3, 5, 6, 7, 4, 4, 7, 7, 2, 4, 4, 7] | |
xor = [3,0,0,7,4,0,7,0,0,0,0,7] | |
flag = [0 for _ in range(12)] | |
for i in range(len(key)-1,-1,-1): | |
if not flag[-1]: | |
flag[i] = circleR_rev(key[i]^key[i-1]^xor[i],circle_R[i]) | |
else: | |
flag[i] = circleR_rev(key[i]^key[i-1]^xor[i]^flag[i+1],circle_R[i]) | |
if not i: | |
flag[i] = circleR_rev(key[i]^xor[i]^flag[i + 1], circle_R[i]) | |
print(''.join(map(chr, flag))) |