hws 填完参赛问卷之后邮件被发到了垃圾箱里面,比赛开打好几个小时了才发现 (悲), 不过成绩还是不错滴,把逆向 ak 啦,第四名耶 (●’◡’●)
别的方向 misc 和 crypto 也稍微看了下,算是逆向之外的闲情雅致:), 但总归是能做出超级简单的题目的,但是 pwn 是真的不会!做不了一点… 不会 pwn 的二进制手只能当逆向手了😂

题目附件: 点击下载
# reverse
# Android
反编译 libjniex.so , 发现这个解密函数,所使用的算法为 SM4
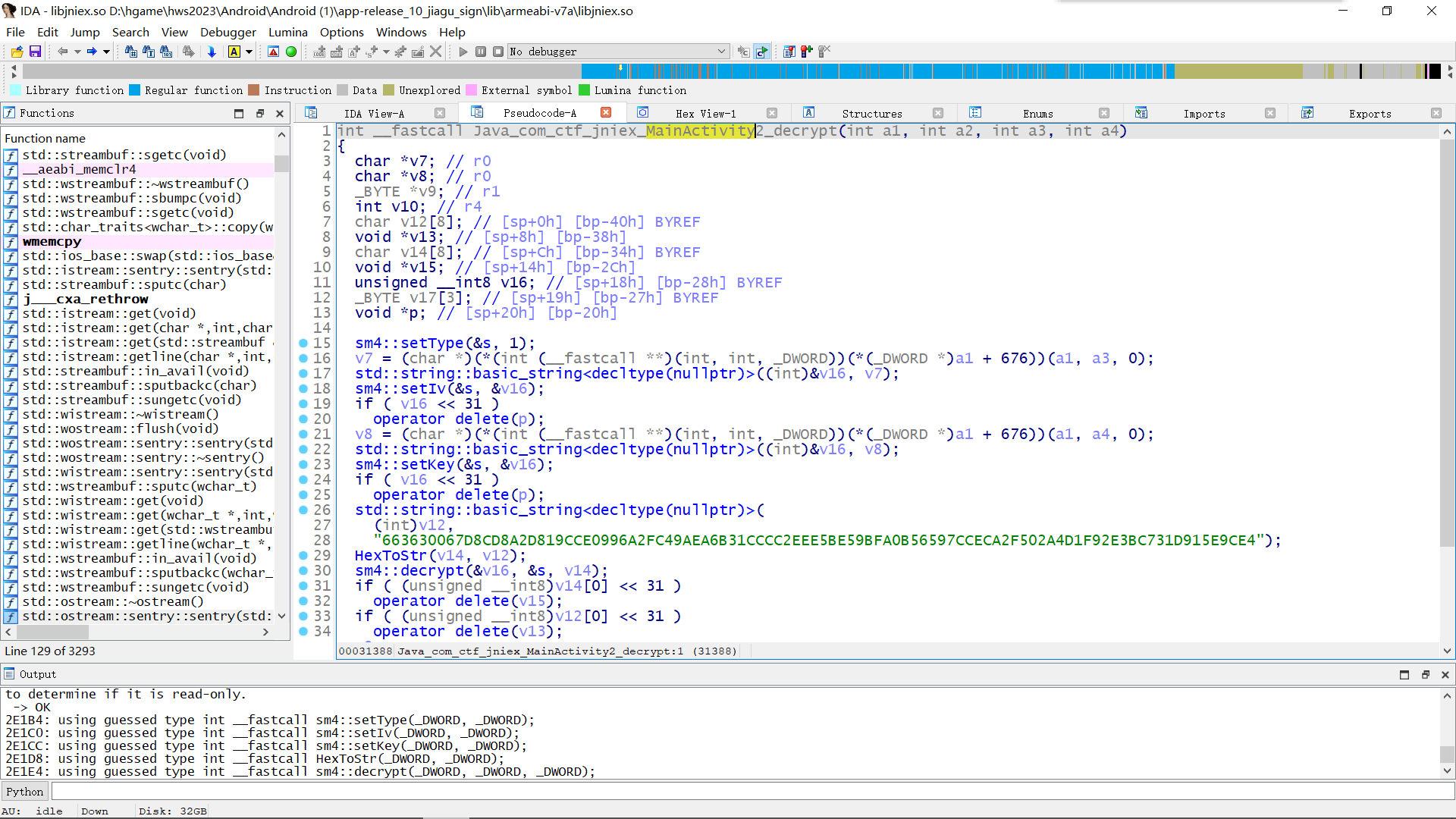
安装 apk, 打开后发现两个特殊字符串 159762dr7vh438sa 和 1313131313131313
于是写一下 exp
import base64 | |
from pysm4 import encrypt_cbc, decrypt_cbc | |
import base64 | |
key = "159762dr7vh438sa" # 密钥 | |
iv = "1313131313131313" | |
cipher_text = bytes.fromhex("663630067D8CD8A2D819CCE0996A2FC49AEA6B31CCCC2EEE5BE59BFA0B56597CCECA2F502A4D1F92E3BC731D915E9CE4") # 加密后的数据 | |
plain_text = decrypt_cbc(base64.b64encode(cipher_text), key, iv) | |
print(plain_text) | |
# flag{just!_enjoy!_the_match!_zyc_2022} |
# Animals
ida 打开 main, 发现有花指令形式如下,用 idapython 修复一下
import idautils | |
import idc | |
def my_nop(addr, endaddr): | |
while addr < endaddr: | |
patch_byte(addr, 0x90) | |
addr += 1 | |
pattern = ["74 15 75 13 8D 44 24 FC 83 F0 22 3B 04 24 74 0A E8 1F 00 00 00 74 04", | |
"74 0A 75 08 E8 10 00 00 00 EB 04 E8", | |
"48 81 EC 08 03 00 00"] | |
for i in range(len(pattern)): | |
cur_addr = 0x406300 | |
end_addr = 0x406E2C | |
while cur_addr < end_addr: | |
cur_addr = idc.find_binary(cur_addr, SEARCH_DOWN, pattern[i]) | |
print("patch address: " + hex(cur_addr)) # 打印提示信息 | |
if cur_addr == idc.BADADDR: | |
break | |
else: | |
my_nop(cur_addr, cur_addr + len(pattern[i].split(' '))) | |
cur_addr = idc.next_head(cur_addr) |
这里出现的常数说明算法应该是 MD5, 而且常数位置不一致,那么这应该是魔改的 md5
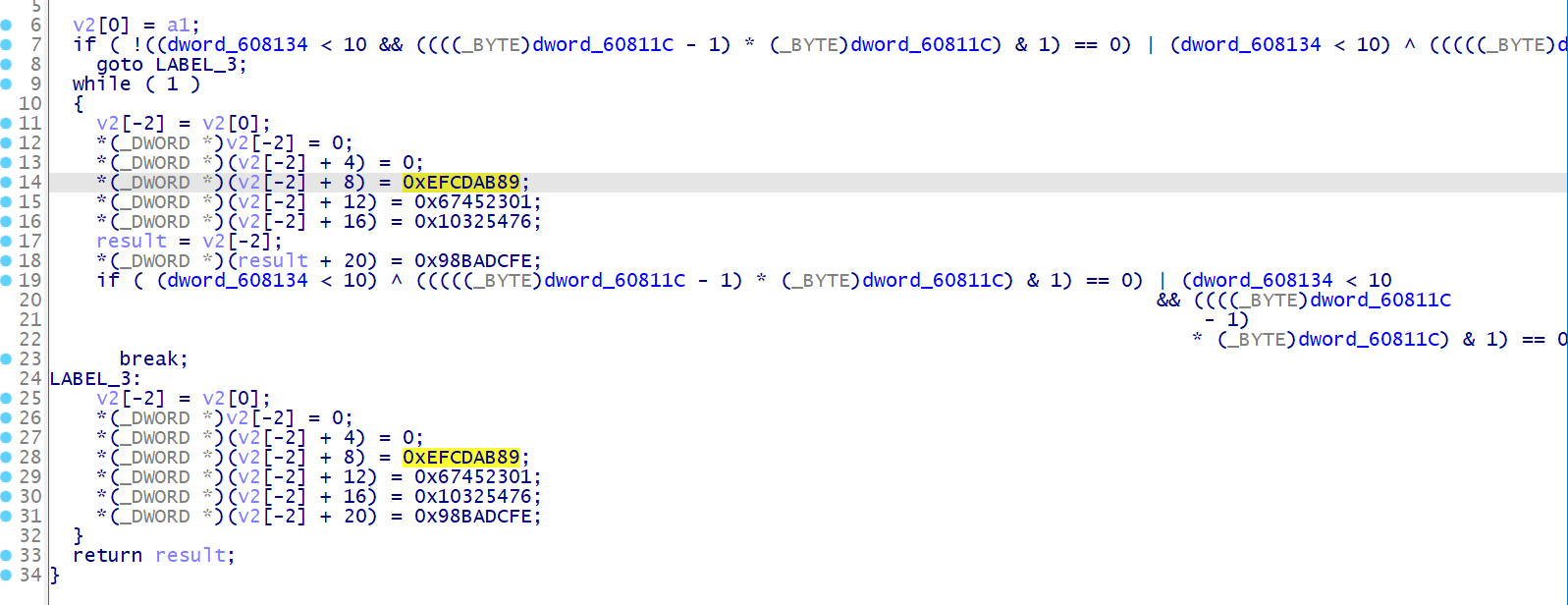
main 函数的前两行有 pthread 反调试
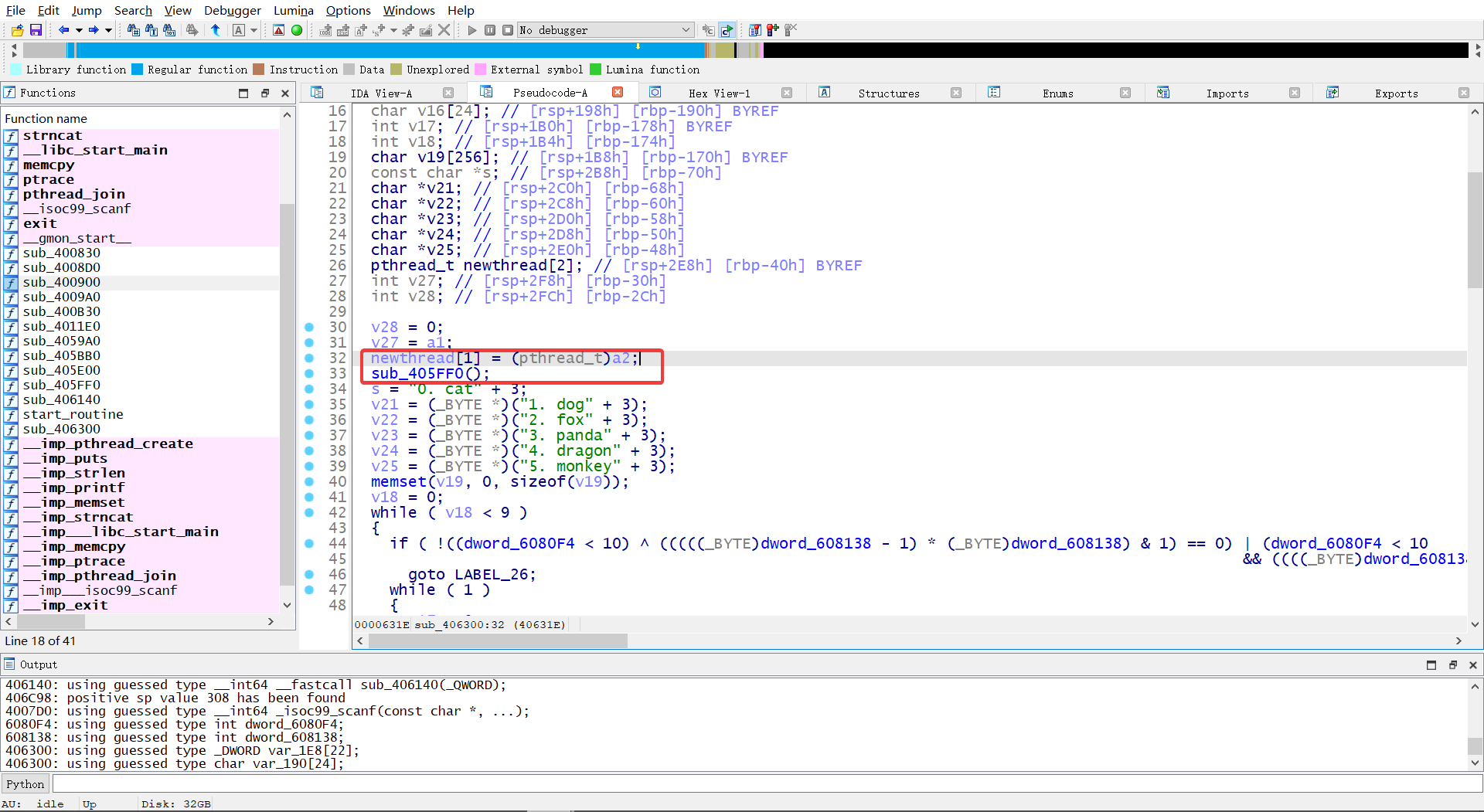
进入 sub_405FF0 把退出逻辑修改使其不退出 jnz short loc_40603E –> jz short loc_40603E
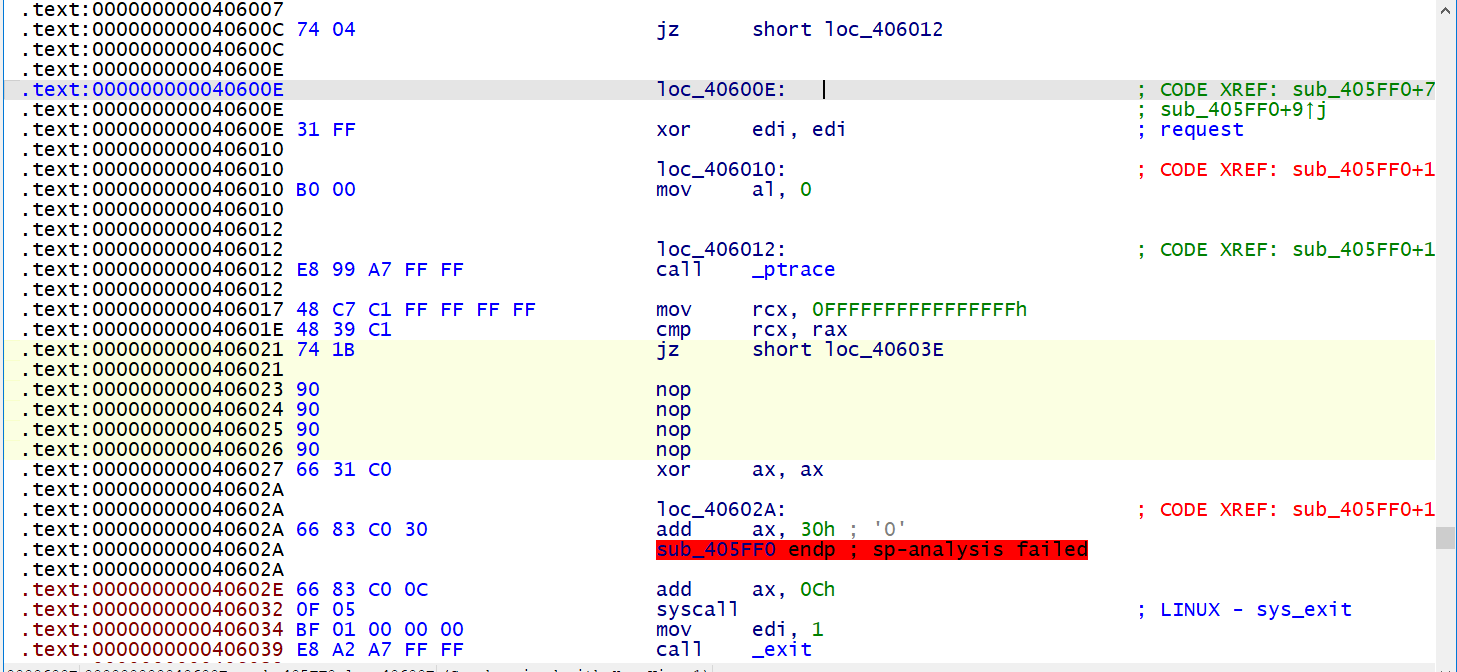
动态调试发现最终比较的数组和静态分析的数组不一致,推测在运行的过程中这个比较的数组进行了修改
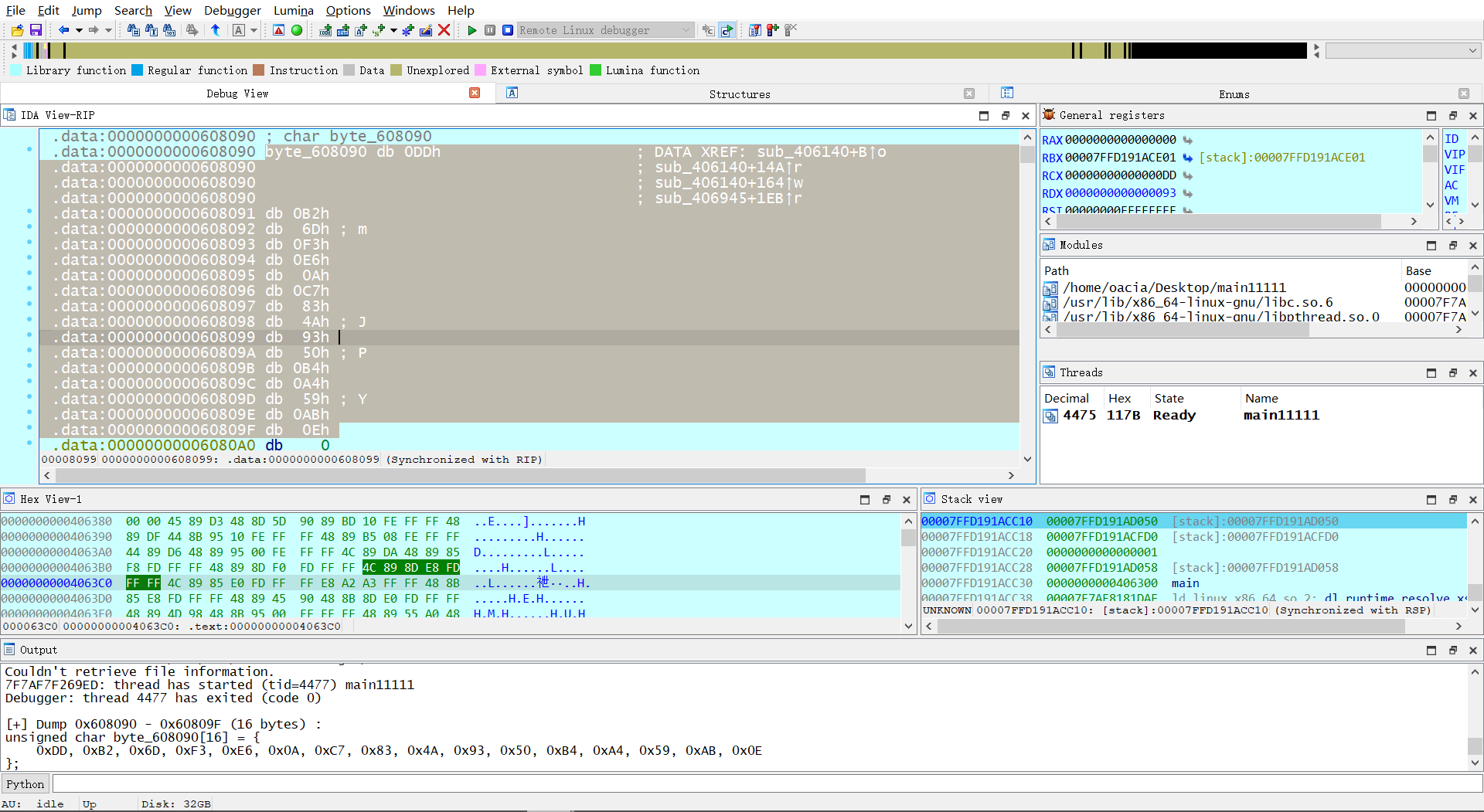
于是得到 exp, 要注意 md5.c 中的常数要和题目中的常数一致
#include <stdio.h> | |
#include <string.h> | |
#include <stdlib.h> | |
#include "md5.h" | |
unsigned char target[16] = { | |
0xDD, 0xB2, 0x6D, 0xF3, 0xE6, 0x0A, 0xC7, 0x83, 0x4A, 0x93, 0x50, 0xB4, 0xA4, 0x59, 0xAB, 0x0E | |
}; | |
void md5_enc(unsigned char encrypt[]){ | |
int i; | |
unsigned char decrypt[16]; | |
MD5_CTX md5; | |
MD5Init(&md5); | |
MD5Update(&md5,encrypt,strlen((char *)encrypt)); | |
MD5Final(&md5,decrypt); | |
//printf("%s\n",encrypt); | |
for(i=0;i<16;i++) | |
{ | |
if(target[i]!=decrypt[i]){ | |
return; | |
} | |
} | |
printf("%s\n",encrypt); | |
exit(2); | |
} | |
void printCombinations(char* str, int index) { | |
if (index == 9) { | |
//printf("%s\n", str); | |
md5_enc(str); | |
return; | |
} | |
char* animal[] = { "cat", "dog", "fox", "panda", "dragon","monkey" }; | |
for (int i = 0; i < 6; i++) { | |
strncat(str,animal[i],strlen(animal[i])); | |
//strcat(str,animal[i]); | |
//printf("%c\n",str[0]); | |
printCombinations(str, index + 1); | |
str[strlen(str) - strlen(animal[i])] = '\0'; | |
} | |
} | |
int main(int argc, char *argv[]) | |
{ | |
char str[60]; | |
str[0] = '\0'; | |
printCombinations(str, 0); | |
return 0; | |
} |
脚本输出 catmonkeydogdragondogcatfoxpandapanda , 那么输入的数字就应该是 051410233
md5 一下得到 flag
flag{839c998c52db6618bb24c346b85a894f}
# E
查一下属性,这个程序是易语言写的
用 ida 插件 E-Decompiler 来静态分析一下
使用插件后因为有中文名右边显示的名称为 __ , 但是我又不太想 patch ida 去修复,所以就索性把所有中文的函数名手工翻译成英文好了
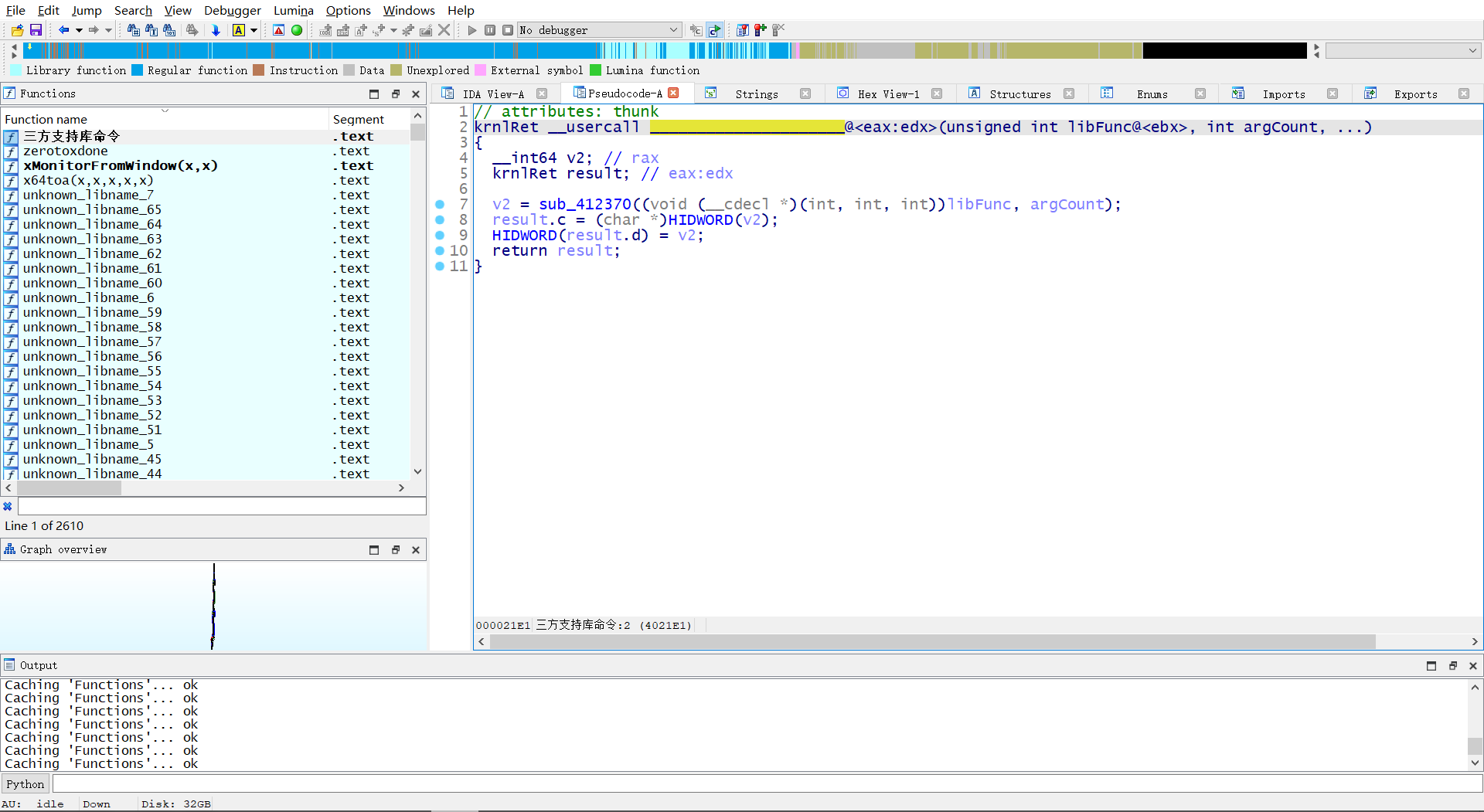
通过交叉引用 wrong 字符串,找到主要函数在 sub_4010C8
分析一下这个函数,加密流程主要将字符串平均分成左右两部分去进行加密

用 python 的话这样表示
import ctypes | |
import string | |
def left_enc(L_str): | |
L_str.value = ((L_str.value << 1) ^ 0xBF) >> 1 | |
return L_str | |
def right_enc(L_str): | |
L_str.value = ((L_str.value << 1) ^ 0x81) >> 1 | |
return L_str | |
text = "0123456789.-" | |
res = string.printable | |
for ch in text: | |
for i in res: | |
out = left_enc(ctypes.c_uint8(ord(i))) | |
if out.value == ord(ch): | |
print(f"{i}==> {ch}",end='') | |
for i in res: | |
out = right_enc(ctypes.c_uint8(ord(i))) | |
if out.value == ord(ch): | |
print(f" <=={i}") | |
# nmlkjiqrstuv | |
''' | |
o==> 0 <==p | |
n==> 1 <==q | |
m==> 2 <==r | |
l==> 3 <==s | |
k==> 4 <==t | |
j==> 5 <==u | |
i==> 6 <==v | |
h==> 7 <==w | |
g==> 8 <==x | |
f==> 9 <==y | |
q==> . <==n | |
r==> - <==m | |
''' |
看了下第三方库识别不出来,就像这个样子

那就下一个易语言,然后把里面的 static_lib/eCalc_static.lib 制作成 ida 可以识别的 sig 文件,用到的工具是这个
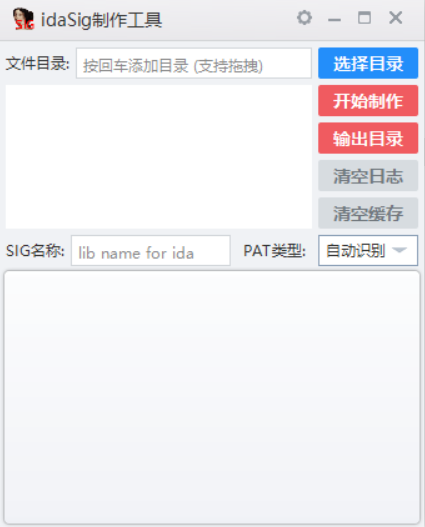
然后 ida 导入这个 sig

导入完成之后就可以分析了

首先研究一下易语言中的大数在内存中的存储方式
写了一个例子方便去分析
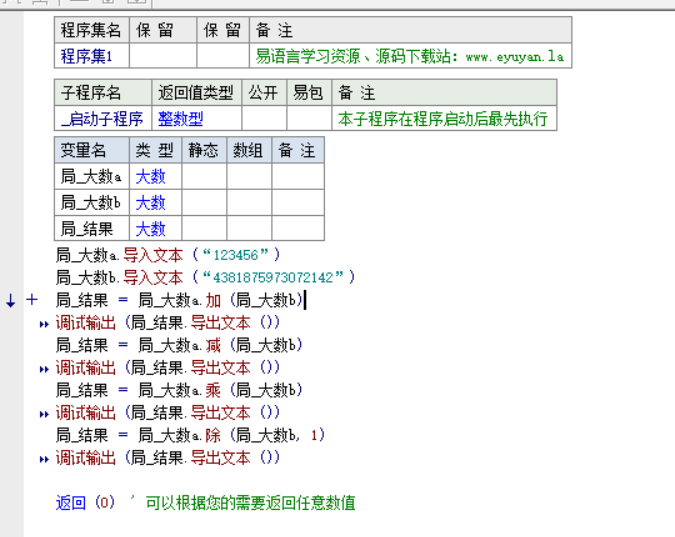
静态编译后动调一下看这个 4381875973072142 是如何存储的
可以发现这个数被分为了两部分 39FFE70Eh 和 byte_1101510
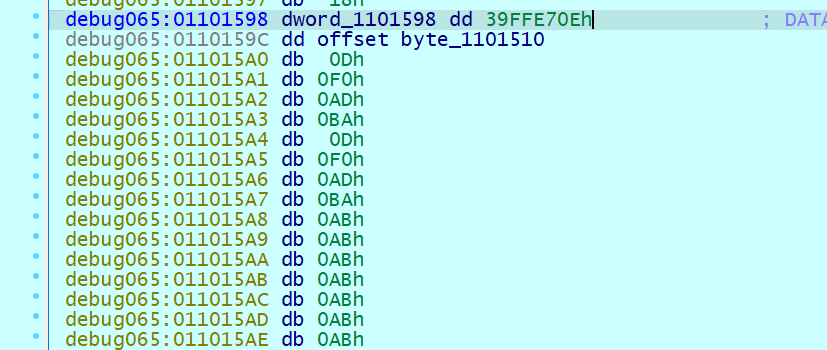
byte_1101510 中的值为 42dcb3h
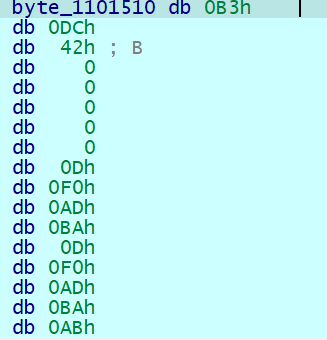
于是我们可以猜测一下大数的存储方式, 0x42dcb3 和 0x39ffe700e 经过什么样子的操作才可以得到 0xf914e66d1ae0e
最终经过一番尝试之后得到
那么就可以得出公式,假设一个大数 bignum 被分成了 p1 , p2 两部分,其中 p1 为高位则有
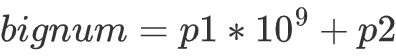
再看一下字符串加密之后,后面循环的内容

经过对大数存储方式的分析,就可以很方便的知道这些要做运算的数都是些什么了
Str1=v69*0x70955fc45
Str2[1]=Str1*v69
Str2[0]=v69*0x34ED1CCB
v62[1]=Str2[0]+0x0D1558
v62[0]=Str2[1]+v62[1]
v61=v70-v62[0]
v69 为循环的变量,v70 为字符串左半部分的数字
整理之后 v61=v70-(v69*0x70955fc45*v69+v69*0x34ED1CCB+0x0D1558)
那要得到 v70 就需要这部分 (v69*0x70955fc45*v69+v69*0x34ED1CCB+0x0D1558) 加回去就可以了
再看一下得到 flag 的条件,那么左半部分就是 v69 从 1 到 800 累加,右半部分就是 v69 从 1 到 900 累加

这一题的左半部分大数运算的循环是有问题的,我们可以详细看看这部分的汇编以及对应的栈指针
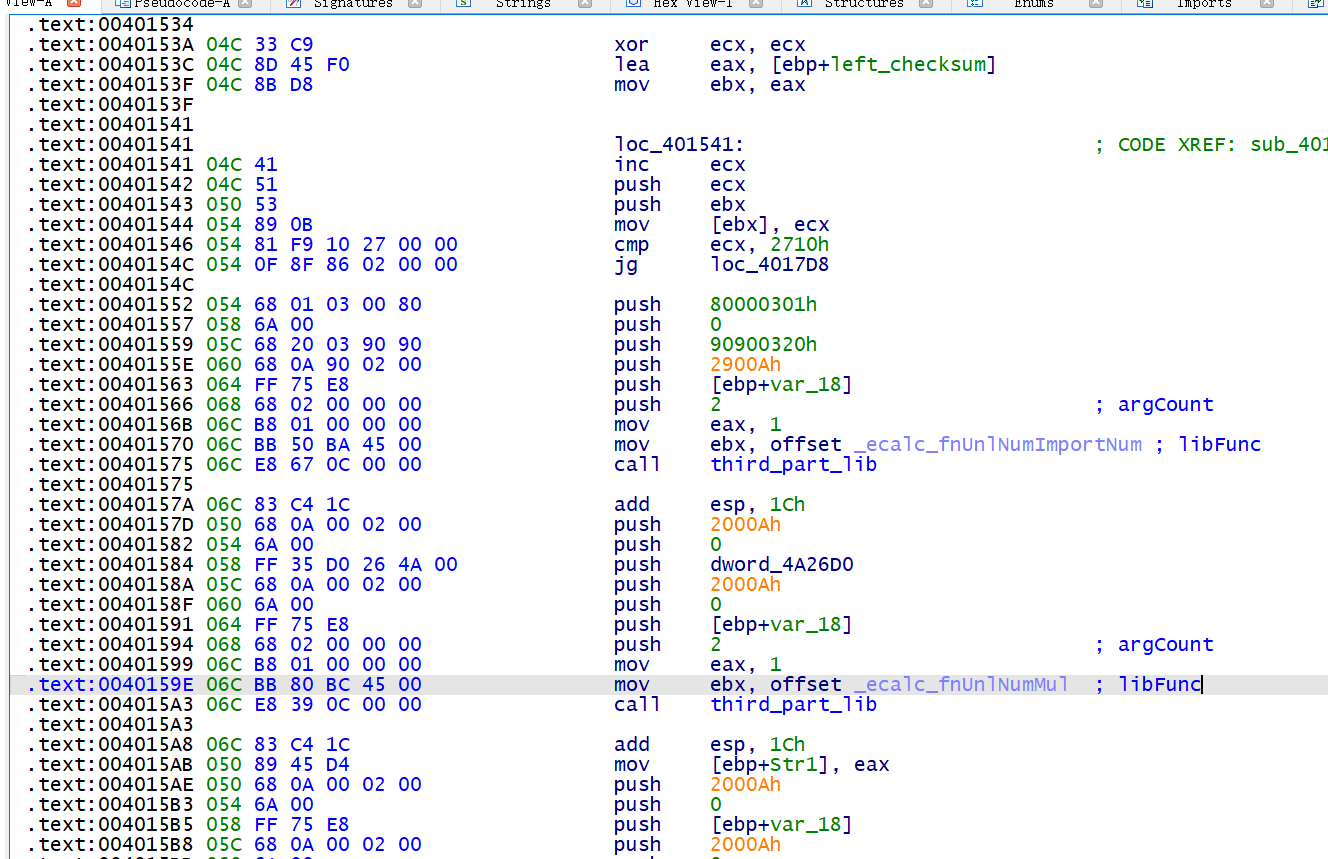
40157A 处的汇编 add esp, 1Ch 将栈顶指针由 6C 移到了 50 , 栈顶指针在 50 指向的栈的内容是什么?找到 401543 处的 push ebx , 这个位置存储的是 [ebp+left_checksum] , 即 leftchecksum 的指针地址
看到 4015AE 处的 push 2000Ah , 这里的指针位置也是 50 , 也就是说,照着题目的汇编执行,本来在栈中存储 [ebp+left_checksum] 的内容将会被覆盖掉,于是程序走到 4017D1 后,不能 pop 出正确的 [ebp+left_checksum] 的值,给 ebx 赋的值是未知的,于是在 401544 处的 mov [ebx], ecx 会产生内存访问异常,所以即使是正确的输入,也不会输出 right 或者 wrong , 因为早在处理输入的字符串的左半部分时,就会因为内存读取异常而退出程序了
所以我把 40157A 处的汇编 add esp, 1Ch patch 成了 add esp, 18h , 让栈顶指针移到 54 这个位置,来保证栈内数据的稳定性,后续的分析也是直接跳过左半部分,而直接去分析右半部分的
而且左半部分 401570 处调用的函数,本应该赋值给 [ebp+var_18] 的 [ebp+left_checksum] 也没有出现,比对一下左右两半部分字符串中相对于循环位置相同的函数调用 (都是循环内的第一行函数函数调用), 发现是并不相同的,似乎是题目出了些问题
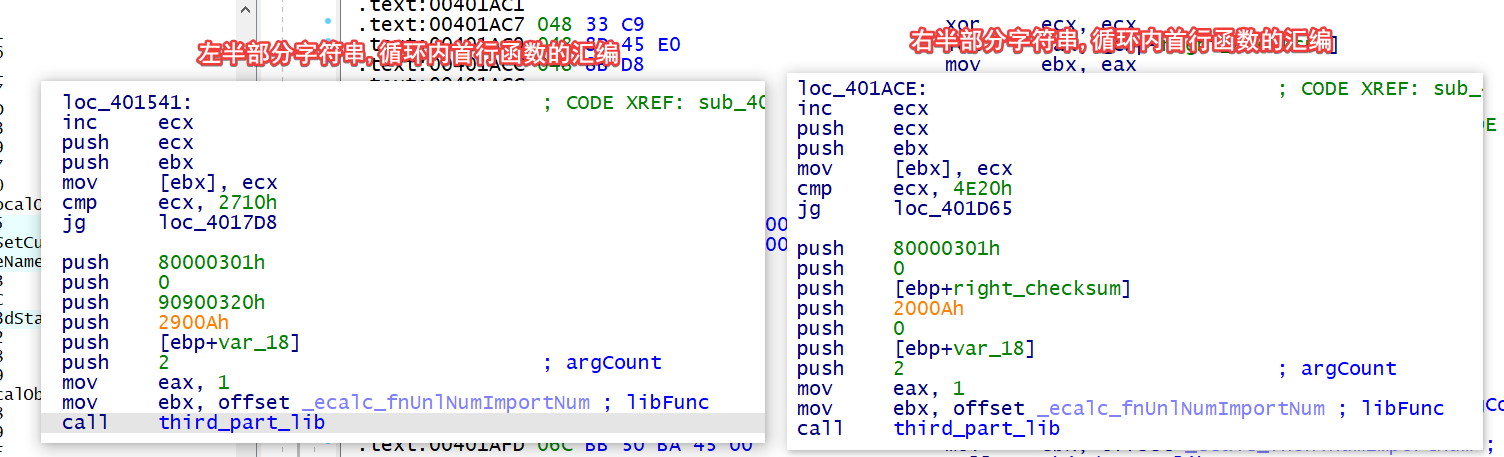
不过还是可以通过类比,得到 flag 的,因为左右两边的加密方式几乎完全相同
解释完题目本身的问题,现在给出 exp
import ctypes | |
import string | |
def left_enc(L_str): | |
L_str.value = ((L_str.value << 1) ^ 0xBF) >> 1 | |
return L_str | |
def right_enc(L_str): | |
L_str.value = ((L_str.value << 1) ^ 0x81) >> 1 | |
return L_str | |
# print(chr(left_enc(ctypes.c_uint8(ord('{'))).value)) | |
# print(chr(right_enc(ctypes.c_uint8(ord('}'))).value)) | |
dic_left = {} | |
dic_right = {} | |
text = "0123456789." | |
res = string.printable | |
for ch in text: | |
for i in res: | |
out = left_enc(ctypes.c_uint8(ord(i))) | |
if out.value == ord(ch): | |
# print(f"{i}==> {ch}",end='') | |
dic_left[ch] = i | |
for i in res: | |
out = right_enc(ctypes.c_uint8(ord(i))) | |
if out.value == ord(ch): | |
# print(f" <=={i}") | |
dic_right[ch] = i | |
# nmlkjiqrstuv | |
''' | |
nnnnnnnnqqqqqqqq | |
ffffffffyyyyyyyy | |
ffffqfffyyyyqyyy | |
999999==>0x11317d8 | |
''' | |
''' | |
o==> 0 <==p | |
n==> 1 <==q | |
m==> 2 <==r | |
l==> 3 <==s | |
k==> 4 <==t | |
j==> 5 <==u | |
i==> 6 <==v | |
h==> 7 <==w | |
g==> 8 <==x | |
f==> 9 <==y | |
q==> . <==n | |
r==> - <==m | |
''' | |
# v61=v70-(v69*0x70955fc45*v69+v69*0x34ED1CCB+0x0D1558) | |
v70 = 0 | |
for v69 in range(1, 801): | |
v70 = v70 + (v69 * 0x70955fc45 * v69 + v69 * 0x34ED1CCB + 0x0D1558) | |
for i in str(v70): | |
print(dic_left[i], end='') | |
# print('') | |
v70 = 0 | |
for v69 in range(1, 901): | |
# v70 = (v69 * 0x70955fc45 * v69 + v69 * 0x34ED1CCB + 0x0D1558) | |
v70 = v70 + (v69 * 0x70955fc45 * v69 + v69 * 0x34ED1CCB + 0x0D1558) | |
# print(v70) | |
for i in str(v70): | |
print(dic_right[i], end='') | |
# jnihhkjnhihomhmhmoowsuvtptwpsxpxrpxqpp |
# crypto
# RSA
在网上找了一下这题和 AntCTF x D^3CTF 2022 的 d3factor 长的很像
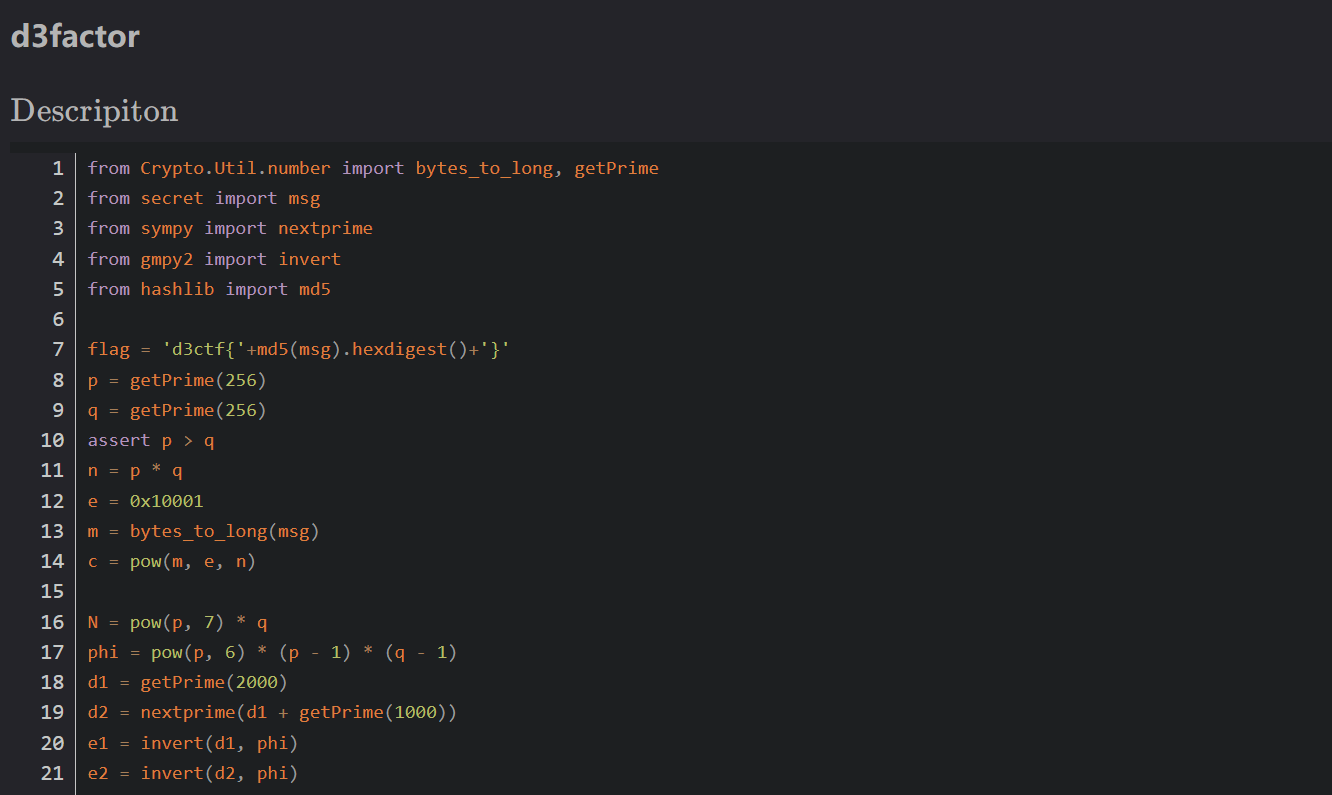
于是就把 exp 的脚本拿过来,参数换成这题给的,就出 flag 了
# sagemath | |
from Crypto.Util.number import * | |
import gmpy2,hashlib | |
N=26989781630503676259502221325791347584607522857769579575297691973258919576768826427059198152035415835627885162613470528107575781277590981314410130242259476764500731263549070841939946410404214950861916808234008589966849302830389937977667872854316531408288338541977868568209278283760692866116947597445559763998608870359453835826711179703215320653445704522573070650642347871171425399227090705774976383452533375854187754721093890020986550939103071021619840797519979671188117673303672023522910200606134989916541289908538417562640981839074992935652363458747488201289997240226553340491203815779083605965873519144351105635977 | |
c=15608493359172313429111250362547316415137342033261379619116685637094829328864086722267534755459655689598026363165606700718051739433022581810982230521098576597484850535770518552787220173105513426779515790426303985414120033452747683669501078476628404455341179818932159581239994489678323564587149645006231756392148052557984581049067156468083162932334692086321511063682574943502393749684556026493316348892705114791740287823927634401828970155725090197482067045119003108806888768161101755244340832271562849138340706213702438667804460812804485276133545408754720942940596865774516864097546006862891145251661268265204662316437 | |
e=65537 | |
e1=8334176273377687778925968652923982846998724107624538105654894737480608040787164942908664678429487595866375466955578536932646638608374859799560790357357355475153852315429988251406716837806949387421402107779526648346112857245251481791000156326311794515247012084479404963628187413781724893173183595037984078029706687141452980915897613598715166764006079337996939237831127877822777298891345240992224457502307777453813403723860370336259768714433691700008761598135158249554720239480856332237245140606893060889458298812027643186014638882487288529484407249417947342798261233371859439003556025622531286607093086262182961900221 | |
e2=22291783101991466901669802811072286361463259096412523019927956845014956726984633944311563809077545336731345629003968417408385538540199052480763352937138063001691494078141034164060073208592072783644252721127901996835233091410441838546235477819239598146496144359952946239328842198897348830164467799618269341456666825968971193729838026760012332020223490546511437879465268118749332615890600046622926159177680882780495663448654527562370133394251859961739946007037825763819500955365636946510343942994301809125029616066868596044885547005547390446468651797783520279531291808102209463733268922901056842903640261702268483580079 | |
r = 7 | |
a = (e2 - e1) * gmpy2.invert(e1*e2,N) % N | |
# assert a < N | |
P.<x> = PolynomialRing(Zmod(N)) | |
f = x - a | |
x = f.small_roots(X = 2^1000,beta = 0.4) | |
x = x[0] | |
k_phi = e1*e2*x - (e2 - e1) | |
p_ = gcd(k_phi,N) | |
p = gmpy2.iroot(int(p_),r - 1)[0] | |
# print(p) | |
q = N // (p**r) | |
# print(q) | |
n = p * q | |
phi_n = (p - 1) * (q - 1) | |
d = gmpy2.invert(e,phi_n) | |
# print(n) | |
m = pow(c,d,n) | |
print(bytes.decode(long_to_bytes(int(m)))) | |
# flag{RSA_1s_s0_ez_4nd_hwser_c4n_bre4k_1t!} |
# misc
# USB
使用脚本得到键盘的输入的字符
import sys, argparse, os | |
class kbpaser: | |
def __init__(self): | |
#tshark 导出文件 | |
self.datafile="kbdatafile.txt" | |
self.presses= [] | |
#Keyboard Traffic Dictionary | |
self.normalKeys = {"04":"a", "05":"b", "06":"c", "07":"d", "08":"e", "09":"f", "0a":"g", "0b":"h", "0c":"i", "0d":"j", "0e":"k", "0f":"l", "10":"m", "11":"n", "12":"o", "13":"p", "14":"q", "15":"r", "16":"s", "17":"t", "18":"u", "19":"v", "1a":"w", "1b":"x", "1c":"y", "1d":"z","1e":"1", "1f":"2", "20":"3", "21":"4", "22":"5", "23":"6","24":"7","25":"8","26":"9","27":"0","28":"<RET>","29":"<ESC>","2a":"<DEL>", "2b":"\t","2c":"<SPACE>","2d":"-","2e":"=","2f":"[","30":"]","31":"\\","32":"<NON>","33":";","34":"'","35":"<GA>","36":",","37":".","38":"/","39":"<CAP>","3a":"<F1>","3b":"<F2>", "3c":"<F3>","3d":"<F4>","3e":"<F5>","3f":"<F6>","40":"<F7>","41":"<F8>","42":"<F9>","43":"<F10>","44":"<F11>","45":"<F12>"} | |
#Press shift | |
self.shiftKeys = {"04":"A", "05":"B", "06":"C", "07":"D", "08":"E", "09":"F", "0a":"G", "0b":"H", "0c":"I", "0d":"J", "0e":"K", "0f":"L", "10":"M", "11":"N", "12":"O", "13":"P", "14":"Q", "15":"R", "16":"S", "17":"T", "18":"U", "19":"V", "1a":"W", "1b":"X", "1c":"Y", "1d":"Z","1e":"!", "1f":"@", "20":"#", "21":"$", "22":"%", "23":"^","24":"&","25":"*","26":"(","27":")","28":"<RET>","29":"<ESC>","2a":"<DEL>", "2b":"\t","2c":"<SPACE>","2d":"_","2e":"+","2f":"{","30":"}","31":"|","32":"<NON>","33":"\"","34":":","35":"<GA>","36":"<","37":">","38":"?","39":"<CAP>","3a":"<F1>","3b":"<F2>", "3c":"<F3>","3d":"<F4>","3e":"<F5>","3f":"<F6>","40":"<F7>","41":"<F8>","42":"<F9>","43":"<F10>","44":"<F11>","45":"<F12>"} | |
def tshark_do(self, pcapfile, filterfield, fieldvalue): | |
if os.name == "nt": | |
if filterfield is not None: | |
command = f"tshark -r {pcapfile} -Y {filterfield} -T fields -e {fieldvalue} > {self.datafile}" | |
else: | |
command = f"tshark -r {pcapfile} -T fields -e {fieldvalue} > {self.datafile}" | |
try: | |
os.system(command) | |
print("tshark执行语句:" + command) | |
print("[+] Found : tshark导出数据成功") | |
except: | |
print("tshark执行语句:" + command) | |
print("[+] Found : tshark导出数据失败") | |
elif os.name == "posix": | |
#sed '/^\s*$/d' 主要是去掉空行 | |
if filterfield not in None: | |
command = f"tshark -r {pcapfile} -Y {filterfield} -T fields -e {fieldvalue} | sed '/^\s*$/d' > {self.datafile}" | |
else: | |
command = f"tshark -r {pcapfile} -T fields -e {fieldvalue} | sed '/^\s*$/d' > {self.datafile}" | |
try: | |
os.system(command) | |
print("tshark执行语句:" + command) | |
print("[+] Found : tshark导出数据成功") | |
except: | |
print("tshark执行语句:" + command) | |
print("[+] Found : tshark导出数据失败") | |
#筛掉无用数据,改变数据格式 | |
def formatkbdata(self): | |
formatfile = open("formatKbdatafile.txt","w") | |
with open(self.datafile, "r") as f: | |
for i in f: | |
# if len(i.strip("\n")) == 8: | |
# Bytes = [i[j:j+2] for j in range(0, len(i.strip("\n")), 2)] | |
# data = ":".join(Bytes) | |
# formatfile.writelines(data+"\n") | |
if len(i.strip("\n")) == 16: | |
Bytes = [i[j:j+2] for j in range(0, len(i.strip("\n")), 2)] | |
data = ":".join(Bytes) | |
formatfile.writelines(data+"\n") | |
formatfile.close() | |
def jiemi(self): | |
print("\n-----开始解密Tshark导出的键盘数据-----\n") | |
# 读取数据 z | |
with open("formatKbdatafile.txt", "r") as f: | |
for line in f: | |
self.presses.append(line[0:-1]) #去掉末尾的 \n | |
# 开始处理 | |
result = [] | |
for press in self.presses: | |
if press == '': | |
continue | |
#thark 版本原因,导出数据格式不同 | |
if ':' in press: | |
Bytes = press.split(":") | |
else: | |
#两两分组 | |
Bytes = [press[i:i+2] for i in range(0, len(press), 2)] | |
print(Bytes) | |
if Bytes[0] == "00": | |
if Bytes[2] != "00" and self.normalKeys.get(Bytes[2]): | |
result.append(self.normalKeys[Bytes[2]]) | |
# print(result) | |
elif int(Bytes[0],16) & 0b10 or int(Bytes[0],16) & 0b100000: # shift key is pressed. | |
if Bytes[2] != "00" and self.normalKeys.get(Bytes[2]): | |
# result.append(self.normalKeys[Bytes[2]]) | |
result.append(self.shiftKeys[Bytes[2]]) | |
else: | |
print("[-] Unknow Key : %s" % (Bytes[0])) | |
print("[+] USB_Found : %s" % (result)) | |
# print(type(result)) | |
flag = 0 | |
for i in range(len(result)): | |
try: | |
a = result.index('<DEL>') | |
del result[a] | |
del result[a - 1] | |
except: | |
pass | |
for i in range(len(result)): | |
try: | |
if result[i] == "<CAP>": | |
flag += 1 | |
result.pop(i) | |
if flag == 2: | |
flag = 0 | |
if flag != 0: | |
result[i] = result[i].upper() | |
except: | |
pass | |
# print ('\n [+] 键盘数据 output :' + "".join (result)) | |
# 删除提取数据文件 | |
rm_stat = eval(input(f"-----是否删除tshark导出的文件 \"{self.datafile}\", 1 or 0-----\n")) | |
if rm_stat == 1: | |
os.remove(self.datafile) | |
if __name__ == "__main__": | |
#我的 vscode 工作区的原因,需要切换到当前目录 | |
pwd = os.path.dirname(__file__) | |
os.chdir(pwd) | |
BANNER = r""" | |
// / / // ) ) // ) ) | |
// / / (( //___/ / ___ __ ___ ___ / ___ | |
// / / \\ / __ ( // ) ) // ) ) // ) ) // ) ) //\ \ | |
// / / ) ) // ) ) // // // / / // // \ \ | |
((___/ / ((___ / / //____/ / ((____ // ((___( ( ((____ // \ \ | |
@MAY1AS | |
""" | |
print(BANNER) | |
argobject = argparse.ArgumentParser(prog="UsbKbCracker", description="""This is a script for decrypt UsbKeyboardData | |
""") | |
argobject.add_argument('-f', "--pcapfile", required=True, help="here is your capturedata file") | |
argobject.add_argument('-e', "--fieldvalue", required=True, help="here is your output_format") | |
argobject.add_argument('-Y', "--filterfield", help="here is your filter") | |
arg = argobject.parse_args() | |
kbparser = kbpaser() | |
# tshark 导出数据,存储在 usbdatafile.txt 内 | |
kbparser.tshark_do(pcapfile=arg.pcapfile, fieldvalue=arg.fieldvalue, filterfield=arg.filterfield) | |
kbparser.formatkbdata() | |
kbparser.jiemi() |
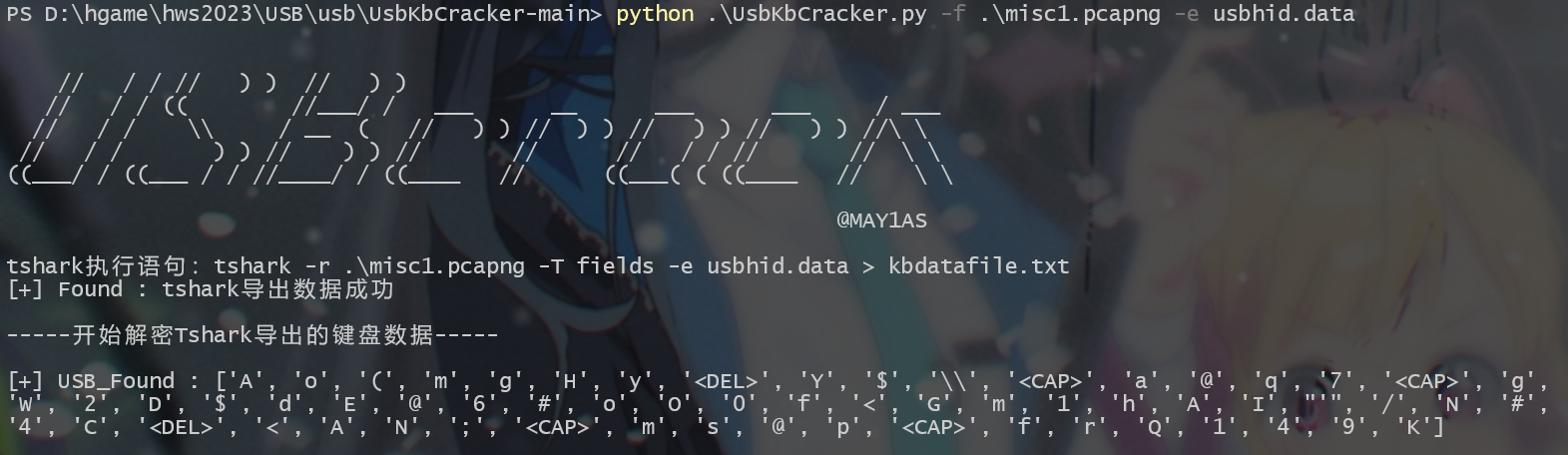
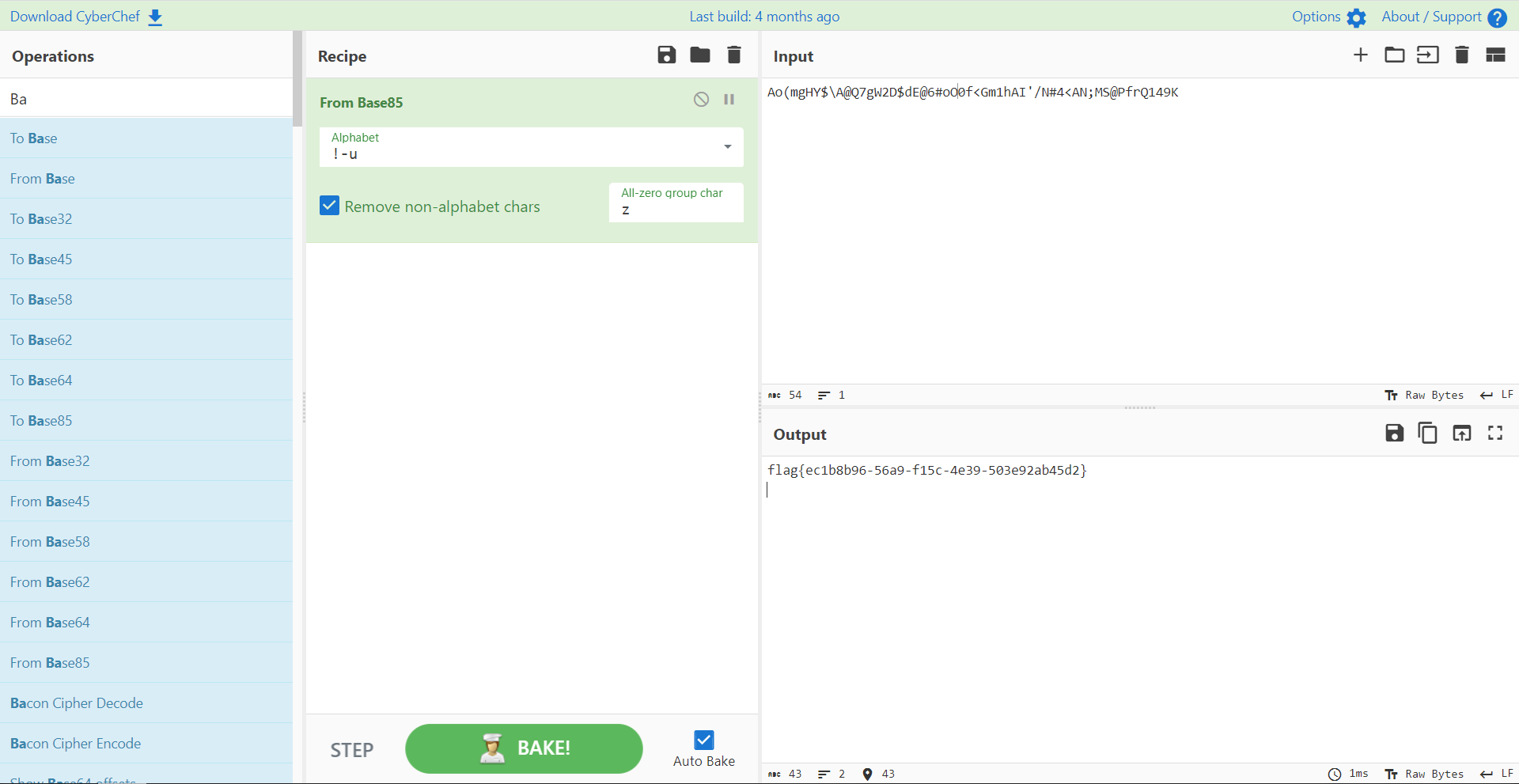
跟着这里的 USB_Found 敲键盘得到 Ao(mgHY$\A@Q7gW2D$dE@6#oO0f<Gm1hAI'/N#4<AN;MS@PfrQ149K
可以发现这是 BASE85 加密
解密一下得到 flag
flag{ec1b8b96-56a9-f15c-4e39-503e92ab45d2}