最近想给自己的博客多增加些好看的图片当背景图,正好这段时间刷抖音看到了好多好看的图片,也把他们保存在收藏夹里面,但是正当我兴致勃勃的想把我收藏夹里面的图片下载下来时,发现工作量真的真的好大!所以索性就写个小脚本来让生活更加轻松咯~
首先我们打开网页版抖音,来到收藏夹,然后疯狂向下拉直到收藏夹的底部
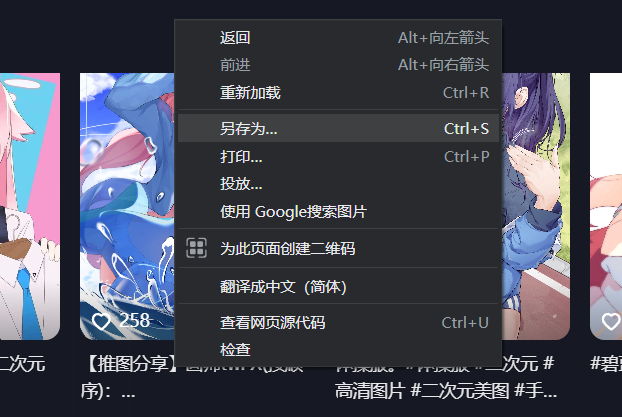
然后在网页上 右键->另存为... 把这个 html 保存为 mhtml 格式
接下来写个简单的小爬虫,抖音里面收藏的图片就下载到电脑上啦~
import re | |
import requests | |
import os | |
from tqdm import tqdm | |
header = { | |
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Mobile Safari/537.36"} | |
def douyin_pic(pid): | |
# 获取 json 数据 | |
p_id = "https://m.douyin.com/web/api/v2/aweme/iteminfo/?reflow_source=reflow_page&item_ids={}&a_bogus=".format(pid) | |
# print(p_id) | |
p_rs = requests.get(url=p_id, headers=header).json() | |
# print(p_rs) | |
# 拿到 images 下的原图片 | |
images = p_rs['item_list'][0]['images'] | |
# 创建 pic 文件夹 | |
if not os.path.exists('douyin/pic'): | |
os.makedirs('douyin/pic') | |
# 下载无水印照片 (遍历 images 下的数据) | |
for index, im in enumerate(images): | |
# 每一条数据下面都有四个原图链接这边用的是第一个 | |
p_req = requests.get(url=im['url_list'][0]) | |
# print(p_req) | |
# 保存图片 | |
# 拿到文件的长度,并把 total 初始化为 0 | |
total = int(p_req.headers.get('content-length', 0)) | |
# 打开当前目录的 fname 文件 (名字你来传入) | |
# 初始化 tqdm,传入总数,文件名等数据,接着就是写入,更新等操作了 | |
with open(f'douyin/pic/{pid}_{str(index)}.jpg', 'wb') as file, tqdm( | |
total=total, | |
unit='iB', | |
desc=f"{pid} 第{index}张图片", | |
unit_scale=True, | |
unit_divisor=1024, | |
) as bar: | |
for data in p_req.iter_content(chunk_size=1024): | |
size = file.write(data) | |
bar.update(size) | |
index += 1 | |
with open('my.mhtml', 'r') as f: | |
data = f.read() | |
data = data.strip().replace("=", "") | |
pic = re.findall(r'https://www.douyin.com/note/(\d+)', data) | |
for p in pic: | |
try: | |
douyin_pic(p) | |
except: | |
print(f"pid {p} went wrong!!!") |